I'm on holiday! And holidays, as seems to be my usual, involve trains!
I was on a train yesterday, wondering how I could possibly fill two hours of leisure time (it's more straightforward these days than a few years ago, when my fellow travellers were less able to occupy their leisure time with books), when help came from a thoroughly unexpected quarter: I got a bug report for swankr.
I wrote swankr nine years ago, mostly
at ISMIR2010. I was about to start
the
Teclo phase
of my ongoing adventures, and an academic colleague had recommended
that I learn R; and the moment where it all fell into place was when I
discovered that R supported handlers and restarts: enough that writing
support for slime's SLDB was a lower-effort endeavour than learning
R's default debugger. I implemented support for the bits of slime
that I use, and also for displaying images in the REPL -- so that I
can present lattice objects as thumbnails of the rendered graph, and
have
the
canned demo of
adding two of them together to get a combined graph: generates “oo”
sounds at every outing, guaranteed! (Now that I mostly use ggplot2,
I need to find a new demo: incrementally building and styling a plot
by adding theme, scale, legend objects and so on is actually useful
but lacks a wow factor.)
SLIME works by exchanging messages between the emacs front-end and the backend lisp; code on the backend lisp is responsible for parsing the messages, executing whatever is needed to support the request, and sending a response. The messages are, broadly, sexp-based, and the message parsing and executing in the backends is mostly portable Common Lisp, delegating to implementation-specific code for specific implementation-specific support needed.
“Mostly portable Common Lisp” doesn't mean that it'll run in R. The R
code is necessarily completely separate, implementing just enough of a
Lisp reader to parse the messages. This works fine, because the
messages themselves are simple; when the front-end sends a message
asking for evaluation for the listener, say, the message is in the
form of a sexp, but the form to evaluate is a string of the
user-provided text: so as long as we have enough of a sexp
reader/evaluator to deal with the SLIME protocol messages, the rest
will be handled by the backend's eval function.
... except in some cases. When slime sends a form to be evaluated
which contains an embedded presentation object, the presentation is
replaced by #.(swank:lookup-presented-object-or-lose 57.) in the
string sent for evaluation. This works fine for Common Lisp backends
– at least provided *read-eval* is true – but doesn't work
elsewhere. One regexp allows us to preprocess the string to evaluate
to rewrite this into something else, but what? Enter cunning plan
number 1: (ab)use backquote.
Backquote? Yes, R has backquote bquote. It also has moderately
crazy function call semantics, so it's possible to: rewrite the string
ob be evaluated to contain unquotations; parse the string into a form;
funcall the bquote function on that form (effectively performing the
unquotations, simulating the read-time evaluation), and then eval
the result. And this would be marvellous except that Philipp Marek
discovered that his own bquote-using code didn't work. Some
investigation later, and the root cause became apparent:
CL-USER> (progn (set 'a 3) (eval (read-from-string "``,a")))
`,a
compare
R> a <- 3; bquote(bquote(.(a)))
bquote(3)
NO NESTED BACKQUOTES?
So, scratch the do.call("bquote", ...) plan. What else is available
to us? It turns out that there's a substitute function, which for
substitute(expr, env)
returns the parse tree for the (unevaluated) expression ‘expr’, substituting any variables bound in ‘env’.
Great! Because that means we can use the regular expression to rewrite the presentation lookup function calls to be specific variable references, then substitute these variable references from the id-to-object environment that we have anyway, and Bob is your metaphorical uncle. So I did that.
The situation is not perfect, unfortunately. Here's some more of the
documentation for substitute:
‘substitute’ works on a purely lexical basis. There is no guarantee that the resulting expression makes any sense.
... and here's some more from do.call:
The behavior of some functions, such as ‘substitute’, will not be the same for functions evaluated using ‘do.call’ as if they were evaluated from the interpreter. The precise semantics are currently undefined and subject to change.
Well that's not ominous at all.
Today, I released sbcl-1.5.0 – with no particular reason for the minor version bump except that when the patch version (we don’t in fact do semantic versioning) gets large it’s hard to remember what I need to type in the release script. In the 17 versions (and 17 months) since sbcl-1.4.0, there have been over 2900 commits – almost all by other people – fixing user-reported, developer-identified, and random-tester-lesser-spotted bugs; providing enhancements; improving support for various platforms; and making things faster, smaller, or sometimes both.
It’s sometimes hard for developers to know what their users think of all of this furious activity. It’s definitely hard for me, in the case of SBCL: I throw releases over the wall, and sometimes people tell me I messed up (but usually there is a resounding silence). So I am running a user survey, where I invite you to tell me things about your use of SBCL. All questions are optional: if something is personally or commercially sensitive, please feel free not to tell me about it! But it’s nine years since the last survey (that I know of), and much has changed since then – I'd be glad to hear any information SBCL users would be willing to provide. I hope to collate the information in late March, and report on any insight I can glean from the answers.
(Don't get too excited by the “success” in the title of this post.)
A brief SBCL RISC-V update this time, as there
have been no train journeys since
the last blog post. Most of what has been
achieved is trivial definitions and rearrangements. We've defined
some
more of the MOVE Virtual Operations that
the compiler needs to be able to move quantities between different
storage classes (from immediate to descriptor-reg, or between
tagged fixnums in descriptor-reg to untagged fixnums in
signed-reg, for example).
We've
defined a debugging printer function,
which wouldn't be needed at this stage except that we're asking the
compiler to print out substantial parts of its internal data
structures. We've reorganized, and not in a desperately good way,
the
definitions of the registers and their storage bases and classes;
this area of code is “smelly”, in that various arguments aren't
evaluate when maybe they should be, which means that some other
structures need to be defined at compile-time so that variables can be
defined at compile-time so that values (in the next form) can be
evaluated at read-time; it's all a bit horrible, and
as Paul said, not friendly to interactive
development. And then a few
more
fairly trivial definitions later,
we are at the point where we have a first trace file from compiling
our very
simple
scratch.lisp file.
Hooray! Here's the assembly code of our foo function:
L10:
VOP XEP-ALLOCATE-FRAME {#<SB!ASSEM:LABEL 1>}
L1:
VOP EMIT-LABEL {#<SB!ASSEM:LABEL 2>}
L2:
VOP EMIT-LABEL {#<SB!ASSEM:LABEL 3>}
L3:
VOP NOTE-ENVIRONMENT-START {#<SB!ASSEM:LABEL 4>}
L4:
L11:
L5:
VOP TYPE-CHECK-ERROR/C #:G0!4[A0] :DEBUG-ENVIRONMENT
{SB!KERNEL:OBJECT-NOT-SIMPLE-ARRAY-FIXNUM-ERROR X}
L12:
byte 50
byte 40
.align 2
L6:
VOP EMIT-LABEL {#<SB!ASSEM:LABEL 7>}
L7:
VOP EMIT-LABEL {#<SB!ASSEM:LABEL 8>}
L8:
VOP NOTE-ENVIRONMENT-START {#<SB!ASSEM:LABEL 9>}
L9:
L13:
L14:
L15:
I hope that everyone can agree that this is a flawless gem of a function.
The next step is probably to start actually defining and using RISC-V instructions, so... stay tuned!
In our first post, I summarized the work of
a few evenings of heat and a few hours on a train, being basically the
boilerplate (parenthesis-infested boilerplate, but boilerplate
nonetheless) necessary to get an SBCL
cross-compiler built. At that point, it was possible to start running
make-host-2.sh, attempting to use the cross-compiler to build the
Lisp sources to go into the initial Lisp image for the new,
target SBCL. Of course, given that all I had
done was create boilerplate, running the cross-compiler was unlikely
to end well: and in fact it barely started well, giving an immediate
error of functions not being defined.
Well, functions not being defined is a fairly normal state of affairs (fans of static type systems look away now!), and easily fixed: we simply define them until they're not undefined any more, ideally with sensible rather than nonsensical contents. That additional constraint, though, gives us our first opportunity to indulge in some actual thought about our target platform.
The routines we have to define include things like functions to return Temporary Names (registers or stack locations) for such things as the lisp return address, the old frame pointer, and the number of arguments to a function: these are things that will be a part of the lisp calling convention, which may or may not bear much relation to the “native” C calling convention. On most SBCL platforms, it doesn't have much in common, with Lisp execution effectively being one large complicated subroutine when viewed from the prism of the C world; the Lisp execution uses a separate stack, which allows us to be sure about what on the stack is a Lisp object and what might not be (making garbage collectors precise on those platforms).
In the nascent RISC-V port, in common with other 32-register ports, these values of interest will be stored in registers, so we need to think about mapping these concepts to the platform registers, documentation of which can be found at the RISC-V site. In particular, let's have a look at logical page 109 (physical page 121) of the user-level RISC-V ISA specification v2.2:
| Register | ABI Name | Description | Saver |
|---|---|---|---|
| x0 | zero | Hard-wired zero | - |
| x1 | ra | Return address | Caller |
| x2 | sp | Stack pointer | Callee |
| x3 | gp | Global pointer | - |
| x4 | tp | Thread pointer | - |
| x5 | t0 | Temporary/Alternate link register | Caller |
| x6-7 | t1-2 | Temporaries | Caller |
| x8 | s0/fp | Saved register/Frame pointer | Callee |
| x9 | s1 | Saved register | Callee |
| x10-11 | a0-1 | Function arguments/return values | Caller |
| x12-17 | a2-7 | Function arguments | Caller |
| x18-27 | s2-11 | Saved registers | Callee |
| x28-31 | t3-6 | Temporaries | Caller |
The table (and the rest of the document) tells us that x0 is a wired
zero: no matter what is written to it, reading from it will always
return 0. That's a useful thing to know; we can now define a storage
class for zero specifically, and define the zero register at offset
0.
The platform ABI uses x1 for a link register (storing the return
address for a subroutine). We may or may not want to use this for our
own return address; I'm not yet sure if we will be able to. For now,
though, we'll keep it reserved for the platform return address,
defining it as register lr in SBCL nomenclature, and use x5 for
our own lisp return address register. Why x5? The ISA definition
for the jalr instruction (Jump And Link Register, logical page 16)
informs us that return address prediction hardware should manipulate
the prediction stack when either x1 or x5 is used as the link
register with jalr, and not when any other register is used; that's
what “Alternate link register” means in the above table. We'll see if
this choice for our lra register,
for Spectre or for worse, gives us
any kind of speed boost – or even if it is tenable at all.
We can define the Number Stack Pointer and Number Frame Pointer
registers, even though we don't need them yet: in SBCL parlance, the
“number” stack is the C stack, and our register table says that those
should be x2 and x8 respectively. Next, for our own purposes we
will need: Lisp stack, frame and old-frame pointer registers; some
function argument registers; and some non-descriptor temporaries.
We'll put those semi-arbitrarily in the temporaries and function
arguments region of the registers; the only bit of forethought here is
to alternate our Lisp arguments and non-descriptor temporaries with
one eye on the “C” RISC-V extension for compressed instructions: if an
instruction uses registers x8–x15 and the “C” extension is
implemented on a particular RISC-V board, the instruction might be
encodable in two bytes instead of four, hopefully reducing instruction
loading and decoding time and instruction cache pressure. (This might
also be overthinking things at this stage). In the spirit of not
overthinking, let's just put nargs on x31 for now.
With
all these decisions implemented,
we hit our first “real” error! Remembering that we are attempting to
compile a very simple file, whose only actual Lisp code involves
returning an element from a specialized array, it's great to hit this
error because it seems to signify that we are almost ready. The
cross-compiler is built knowing that some functions (usually as a
result of code transformations) should never be compiled as calls, but
should instead be /translated/ using one of our Virtual OPerations.
data-vector-ref, which the aref in
our
scratch.lisp file
translates to because of the type declarations, is one such function,
so
we
need to define it:
and also define it in such a way that it will be used no matter what
the current compiler policy, hence the :policy :fast-safe addition
to the reffer macro. (That, and many other such :policy
declarations, are dotted around everywhere in the other backends; I
may come to regret having taken them out in the initial boilerplate
exercise.)
And then, finally, because there's always an excuse for a good
cleanup: those float array VOPs, admittedly without :generator
bodies, look too similar: let's have
a
define-float-vector-frobs macro to
tidy things up. (They may not remain that tidy when we come to
actually implement them). At this point, we have successfully
compiled one Virtual OPeration! I know this, because the next error
from running the build with all this is about call-named, not
data-vector-set. Onward!
I'm on a train! (Disclaimer: I'm not on a train any more.)
What better thing to do, during the hot, hot July days, thank something semi-mechanical involving very little brain power? With student-facing work briefly calming down (we've just about weathered the storm of appeals and complaints following the publication of exam results), and the all-too-brief Summer holidays approaching, I caught myself thinking that it wasn't fair that Doug and his team should have all the fun of porting SBCL to a new architecture; I want a go, too! (The fact that I have no time notwithstanding.)
But, to what? 64-bit powerpc is definitely on the move; I've missed that boat. SBCL already supports most current architectures, and “supports” a fair number of obsolete ones too. One thought that did catch my brain, though, was prompted by the recent publication by ARM of a set of claims purporting to demonstrate the dangers of the RISC-V architecture, in comparison to ARM's own. Well, since SBCL already runs on 32-bit and 64-bit ARM platforms, how hard could porting to RISC-V be?
I don't know the answer to that yet! This first post merely covers the straightforward – some might even say “tedious” – architecture-neutral changes required to get SBCL to the point that it could start about considering compiling code for a new backend.
The SBCL build has roughly seven phases (depending a bit on how you count):
- build configuration;
- build the cross-compiler using the host Lisp, generating target-specific header files;
- build the runtime and garbage collector using a C compiler and platform assembler, generating an executable;
- build the target compiler using the cross-compiler, generating target-specific fasl files;
- build the initial ("cold") image, using the genesis program to simulate the effect of loading fasl files, generating a target Lisp memory image;
- run all the code that stage 5 delayed because it couldn't simulate the effects of loading fasls (e.g. many side-effectful top-level forms);
- build everything else, primarily PCL (a full implementation CLOS) and save the resulting image.
1. Define a keyword for a new backend architecture
Probably the most straightforward thing to do, and something that
allows me to (pretty much) say that we're one seventh of the way
there: defining a new keyword for a new backend architecture is
almost as simple as adding a line or two to
make-config.sh.
Almost.
We run some devious dastardly consistency checks on our target
*features*, and those need to be updated too. This gets
make-config.sh running, and allows make-host-1.sh to run its
consistency checks.
2. Construct minimal backend-specific files
Phase 2, building the cross-compiler, sounds like something straightforward: after all, if we don't have the constraint that the cross-compiler will do anything useful, not even run, then surely just producing minimal files where the build system expects to find them will do, and Lisp’s usual late-binding nature will allow us to get away with the rest. No?
Well, that could have been the case, but SBCL itself does impose some constraints, and the minimal files are a lot less minimal than you might think. The translation of IR2 (second intermediate representation) to machine code involves calling a number of VOPs (virtual operations) by name: and those calls by name perform compile-time checking that the virtual operation template name already exists. So we have to define stub VOPs for all those virtual operations called by name, including those in optimizing vector initialisation, for all of our specialised vector types. These minimal definitions do nothing other than pacify the safety checks in the cross-compiler code.
Phase 2 also generates a number of header files used in the
compilation of the C-based runtime, propagating constant and object
layout definitions to the garbage collector and other support
routines. We won't worry about that for now; we just have to ignore
an error about this at first-genesis time for a while. And with this,
make-host-1.sh runs to completion.
4. Build the target compiler using the cross-compiler
At this point, we have a compiler backend that compiles. It almost
certainly doesn't run, and even when it does run, we will want to ask
it to compile simple forms of our choosing. For now, we
just
add a new file to
the start of the build order, and put in a very simple piece of code,
to see how we get on. (Spoiler alert: not very well). We've added
the :trace-file flag so that the cross-compiler will print
information about its compilation, which will be useful as and when we
get as far as actually compiling things.
The next steps, moving beyond the start of step 4, will involve making decisions about how we are going to support sbcl on RISC-V. As yet, we have not made any decisions about register function (some of those, such as the C stack and frame pointer, will be dictated by the platform ABI, but many won't, such as exactly how we will partition the register set), or about how the stack works (again, the C stack will be largely determined, but Lisp will have its own stack, kept separate for ease of implementating garbage collection).
(Observant readers will note that phase 3 is completely unstarted. It's not necessary yet, though it does need to be completed for phase 4 to run to completion, as some of the cross-compilation depends on information about the runtime memory layout. Some of the details in phase 3 depend on the decisions made in phase 4, though, so that's why I'm doing things in this order, and not, say, because I don't have a RISC-V machine to run anything on -- it was pleasantly straightforward to bring up Fedora under QEMU which should be fine as a place to get started.)
And this concludes the initial SBCL porting work that can be done with very little brain. I do not know where, if anywhere, this effort will go; I am notionally on holiday, and it is also hot: two factors which suggest that work on this, if any, will be accomplished slowly. I'd be very happy to collaborate, if anyone else is interested, or else plod along in my own slow way, writing things up as I go.
Since
approximately forever,
sbcl has advertised the possibility of tracing
individual methods of a generic function by passing :methods t as an
argument to trace. Until
recently, tracing methods was only supported using the :encapsulate
nil style of tracing, modifying the compiled code for function
objects directly.
For a variety of reasons, the alternative :encapsulate t
implementation of tracing, effectively wrapping the function with some
code to run around it, is more robust. One problem with :encapsulate
nil tracing is that if the object being traced is a closure, the
modification of the function's code will affect all of the closures,
not just any single one – closures are distinct objects with distinct
closed-over environments, but they share the same execuable code, so
modifying one of them modifies all of them. However, the
implementation of method tracing I wrote in 2005 – essentially,
finding and tracing the method functions and the method fast-functions
(on which more later) – was fundamentally incompatible with
encapsulation; the method functions are essentially never called by
name by CLOS, but by more esoteric means.
What are those esoteric means, I hear you ask?! I'm glad I can hear
you. The Metaobject Protocol defines a method calling convention,
such that method calls receive as two arguments firstly: the entire
argument list as the method body would expect to handle; and secondly:
the list of sorted applicable next methods, such that the first
element is the method which should be invoked if the method
uses
call-next-method. So
a method function conforming to this protocol has to:
- destructure its first argument to bind the method parameters to the arguments given;
- if
call-next-methodis used, reconstruct an argument list (in general, because the arguments to the next method need not be the same as the arguments to the existing method) before calling the next method’s method-function with the reconstructed argument list and the rest of the next methods.
But! For a given set of actual arguments, for that call, the set of
applicable methods is known; the precedence order is known; and, with
a bit of bookkeeping in the implementation
of defmethod, whether any
individual method actually calls call-next-method is known. So it
is possible, at the point of calling a generic-function with a set of
arguments, to know not only the first applicable method, but in fact
all the applicable methods, their ordering, and the combination of
those methods that will actually get called (which is determined by
whether methods invoke call-next-method and also by the generic
function’s method combination).
Therefore, a sophisticated (and by “sophisticated” here I mean
“written by the wizards
at Xerox PARC)”)
implementation of CLOS can compile an effective method for a given
call, resolve all the next-method calls, perform
some
extra optimizations on
slot-value and slot
accessors, improve the calling convention (we no longer need the list
of next methods, but only a single next effective-method, so we can
spread the argument list once more), and cache the resulting function
for future use. So the one-time cost for each set of applicable
methods generates an optimized effective method, making use of
fast-method-functions with the improved calling convention.
Here's the trick, then: this effective method is compiled into a chain
of method-call and fast-method-call objects, which call their
embedded functions. This, then, is ripe for encapsulation; to allow
method tracing, all we need to do is arrange at
compute-effective-method time that those embedded functions are
wrapped in code that performs the tracing, and that any attempt to
untrace the generic function (or to modify the tracing parameters)
reinitializes the generic function instance, which clears all the
effective method caches. And then Hey Bob, Your Uncle’s Presto! and
everything works.
(defgeneric foo (x)
(:method (x) 3))
(defmethod foo :around ((x fixnum))
(1+ (call-next-method)))
(defmethod foo ((x integer))
(* 2 (call-next-method)))
(defmethod foo ((x float))
(* 3 (call-next-method)))
(defmethod foo :before ((x single-float))
'single)
(defmethod foo :after ((x double-float))
'double)
Here's a generic function foo with moderately complex methods. How
can we work out what is going on? Call the method tracer!
CL-USER> (foo 2.0d0)
0: (FOO 2.0d0)
1: ((SB-PCL::COMBINED-METHOD FOO) 2.0d0)
2: ((METHOD FOO (FLOAT)) 2.0d0)
3: ((METHOD FOO (T)) 2.0d0)
3: (METHOD FOO (T)) returned 3
2: (METHOD FOO (FLOAT)) returned 9
2: ((METHOD FOO :AFTER (DOUBLE-FLOAT)) 2.0d0)
2: (METHOD FOO :AFTER (DOUBLE-FLOAT)) returned DOUBLE
1: (SB-PCL::COMBINED-METHOD FOO) returned 9
0: FOO returned 9
9
This mostly works. It doesn’t quite handle all cases, specifically
when the CLOS user adds a method and implements call-next-method for
themselves:
(add-method #'foo
(make-instance 'standard-method
:qualifiers '()
:specializers (list (find-class 'fixnum))
:lambda-list '(x)
:function (lambda (args nms) (+ 2 (funcall (sb-mop:method-function (first nms)) args (rest nms))))))
CL-USER> (foo 3)
0: (FOO 3)
1: ((METHOD FOO :AROUND (FIXNUM)) 3)
2: ((METHOD FOO (FIXNUM)) 3)
2: (METHOD FOO (FIXNUM)) returned 8
1: (METHOD FOO :AROUND (FIXNUM)) returned 9
0: FOO returned 9
9
In this trace, we have lost the method trace from the direct call to
the method-function, and calls that that function makes; this is
the cost of performing the trace in the effective method, though a
mitigating factor is that we have visibility of method combination
(through the (sb-pcl::combined-method foo) line in the trace above).
It would probably be possible to do the encapsulation in the method
object itself, by modifying the function and the fast-function, but
this requires rather more book-keeping and (at least theoretically)
breaks the object identity: we do not have licence to modify the
function stored in a method object. So, for now, sbcl has this
imperfect solution for users to try (expected to be in sbcl-1.4.9,
probably released towards the end of June).
(I can't really believe it’s taken me twelve years to do this. Other implementations have had this working for years. Sorry!)
At the 2018 European Lisp Symposium, the most obviously actionable feedback for SBCL from a presentation was from Didier's remorseless deconstruction of SBCL's support for method combinations (along with the lack of explicitness about behavioural details in the ANSI CL specification and the Art of the Metaobject Protocol). I don't think that Didier meant to imply that SBCL was particularly bad at method combinations, compared with other available implementations – merely that SBCL was a convenient target. And, to be fair, there was a bug report from a discussion with Bruno Haible back in SBCL's history – May/June 2004, according to my search – which had languished largely unfixed for fourteen years.
I said that I found the Symposium energising.
And what better use to put that energy than addressing user feedback?
So, I spent a bit of time earlier this month thinking, fixing and
attempting to work out what behaviours might actually be useful. To
be clear, SBCL’s support for define-method-combination was (probably)
standards-compliant in the usual case, but if you follow the links
from above, or listen to Didier’s talk, you will be aware that that’s
not saying all that much, in that almost nothing is specified about
behaviours under redefinition of method combinations.
So, to start with, I solved the cache invalidation (one of
the
hardest problems in Computer Science),
making sure that discriminating functions and effective methods are
reset and invalidated for all affected generic functions. This was
slightly complicated by the strategy that SBCL has of distinguishing
short and long method-combinations with distinct classes (and distinct
implementation strategies
for
compute-effective-method);
but this just needed to be methodical and careful. Famous last words:
I think that all method-combination behaviour in SBCL is now coherent
and should meet user expectations.
More interesting, I think, was coming up with test cases for desired
behaviours. Method combinations are not, I think, widely used in
practice; whether that is because of lack of support, lack of
understanding or lack of need of what they provide, I don't know. (In
fact in conversations at ELS we discussed another possibility, which
is that everyone is more comfortable customising
compute-effective-method instead – both that and
define-method-combination provide ways for inserting arbitrary code
for the effect of a generic function call with particular arguments.
But what this means is that there isn’t, as far as I know at least, a
large corpus of interesting method combinations to play with.
One interesting one which came up: Bike on #lisp designed
an
implementation using method-combinations of finite state machines,
which I adapted to add to SBCL’s test suite. My version looks like:
(define-method-combination fsm (default-start)
((primary *))
(:arguments &key start)
`(let ((state (or ,start ',default-start)))
(restart-bind
(,@(mapcar (lambda (m) `(,(first (method-qualifiers m))
(lambda ()
(setq state (call-method ,m))
(if (and (typep state '(and symbol (not null)))
(find-restart state))
(invoke-restart state)
state))))
primary))
(invoke-restart state))))
and there will be more on this use
of restart-bind in a
later post, I hope. Staying on the topic of method combinations, how
might one use this fsm method combination? A simple example might
be to recognize strings with an even number of #\a characters:
;;; first, define something to help with all string parsing
(defclass info ()
((string :initarg :string)
(index :initform 0)))
;;; then the state machine itself
(defgeneric even-as (info &key &allow-other-keys)
(:method-combination fsm :yes))
(defmethod even-as :yes (info &key)
(with-slots ((s string) (i index)) info
(cond ((= i (length s)) t) ((char= (char s i) #\a) (incf i) :no) (t (incf i) :yes))))
(defmethod even-as :no (info &key)
(with-slots ((s string) (i index)) info
(cond ((= i (length s)) nil) ((char= (char s i) #\a) (incf i) :yes) (t (incf i) :no))))
(Exercise for the reader: adapt this to implement a Turing Machine)
Another example of (I think) an interesting method combination was one which I came up with in the context of generalized specializers, for an ELS a while ago: the HTTP Request method-combination to be used with HTTP Accept specializers. I'm interested in more! A github search found some examples before I ran out of patience; do you have any examples?
And I have one further question. The method combination takes
arguments at generic-function definition time (the :yes in
(:method-combination fsm :yes)). Normally, arguments to things are
evaluated at the appropriate time. At the moment, SBCL (and indeed
all other implementations I tested, but that's not strong evidence
given the shared heritage) do not evaluate the arguments to
:method-combination – treating it more like a macro call than a
function call. I’m not sure that is the most helpful behaviour, but
I’m struggling to come up with an example where the other is
definitely better. Maybe something like
(let ((lock (make-lock)))
(defgeneric foo (x)
(:method-combination locked lock)
(:method (x) ...)))
Which would allow automatic locking around the effective method of
FOO through the method combination? I need to think some more here.
In any case: the method-combination fixes are in the current SBCL
master branch, shortly to be released as sbcl-1.4.8. And there is
still time (though not very much!) to apply for
the
many jobs advertised
at
Goldsmiths Computing –
what better things to do on a Bank Holiday weekend?
I presented some of the work on teaching algorithms and data structures at the 2018 European Lisp Symposium
Given that I wanted to go to the symposium (and I’m glad I did!), the most economical method for going was if I presented research work – because then there was a reasonable chance that my employer would fund the expenses (spoiler: they did; thank you!). It might perhaps be surprising to hear that they don’t usually directly fund attending events where one is not presenting; on the other hand, it’s perhaps reasonable on the basis that part of an academic’s job as a scholar and researcher is to be creating and disseminating new knowledge, and of course universities, like any organizations, need to prioritise spending money on things which bring value or further the organization’s mission.
In any case, I found that I wanted to write about the teaching work that I have been doing, and in particular I chose to write about a small, Lisp-related aspect. Specifically, it is now fairly normal in technical subjects to perform a lot of automated testing of students; it relieves the burden on staff to assess things which can be mechanically assessed, and deliver feedback to individual students which can be delivered automatically; this frees up staff time to perform targeted interventions, give better feedback on more qualitative aspects of the curriculum, or work fewer weekends of the year. A large part of my teaching work for the last 18 months has been developing material for these automated tests, and working on the infrastructure underlying them, for my and colleagues’ teaching.
So, the more that we can test automatically and meaningfully, the
more time we have to spend on other things. The main novelty here,
and the lisp-related hook for the paper I submitted to ELS, was being
able to give meaningful feedback on numerical answer questions which
probed whether students were developing a good mental model of the
meaning of pseudocode. That’s a bit vague; let’s be specific and
consider the break and continue keywords:
x ← 0
for 0 ≤ i < 9
x ← x + i
if x > 17
continue
end if
x ← x + 1
end for
return x
The above pseudocode is typical of what a student might see; the
question would be “what does the above block of pseudocode return?”,
which is mildly arithmetically challenging, particularly under time
pressure, but the conceptual aspect that was being tested here was
whether the student understood the effect of continue. Therefore,
it is important to give the student specific feedback; the more
specific, the better. So if a student answered 20 to this question
(as if the continue acted as a break), they would receive a
specific feedback message reminding them about the difference between
the two operators; if they answered 45, they received a message
reminding them that continue has a particular meaning in loops; and
any other answers received generic feedback.
Having just one of these questions does no good, though. Students will go to almost any lengths to avoid learning things, and it is easy to communicate answers to multiple-choice and short-answer questions among a cohort. So, I needed hundreds of these questions: at least one per student, but in fact by design the students could take these multiple-chocie quizzes multiple times, as they are primarily an aid for the students themselves, to help them discover what they know.
Now of course I could treat the above pseudocode fragment as a
template, parameterise it (initial value, loop bounds, increment) and
compute the values needing the specific feedback in terms of the
values of the parameters. But this generalizes badly: what happens
when I decide that I want to vary the operators (say to introduce
multiplication) or modify the structure somewhat (e.g. by swapping
the two increments before and after the continue)? The
parametrization gets more and more complicated, the chances of (my)
error increase, and perhaps most importantly it’s not any fun.
Instead, what did I do? With some sense of grim inevitability, I
evolved (or maybe accreted) an interpreter (in emacs lisp) for a
sexp-based representation of this pseudocode. At the start of the
year, it's pretty simple; towards the end it has developed into an
almost reasonable mini-language. Writing the interpreter is
straightforward, though the way it evolved into one gigantic case
statement for supported operators rather than having reasonable
semantics is a bit of a shame; as a bonus, implementing a
pretty-printer for the sexp-based pseudocode, with correct indentation
and keyword highlighting, is straightforward. Then armed with the
pseudocode I will ask the students to interpret, I can mutate it in
ways that I anticipate students might think like (replacing continue
with break or progn) and interpret that form to see which wrong
answer should generate what feedback.
Anyway, that was the hook. There's some evidence in the paper that the general approach of repeated micro-assessment, and also the the consideration of likely student mistakes and giving specific feedback, actually works. And now that the (provisional) results are in, how does this term compare with last term? We can look at the relationship between this term’s marks and last term’s. What should we be looking for? Generally, I would expect marks in the second term’s coursework to be broadly similar to the marks in the first term – all else being equal, students who put in a lot of effort and are confident with the material in term 1 are likely to have an easier time integrating the slightly more advanced material in term 2. That’s not a deterministic rule, though; some students will have been given a wake-up call by the term 1 marks, and equally some students might decide to coast.
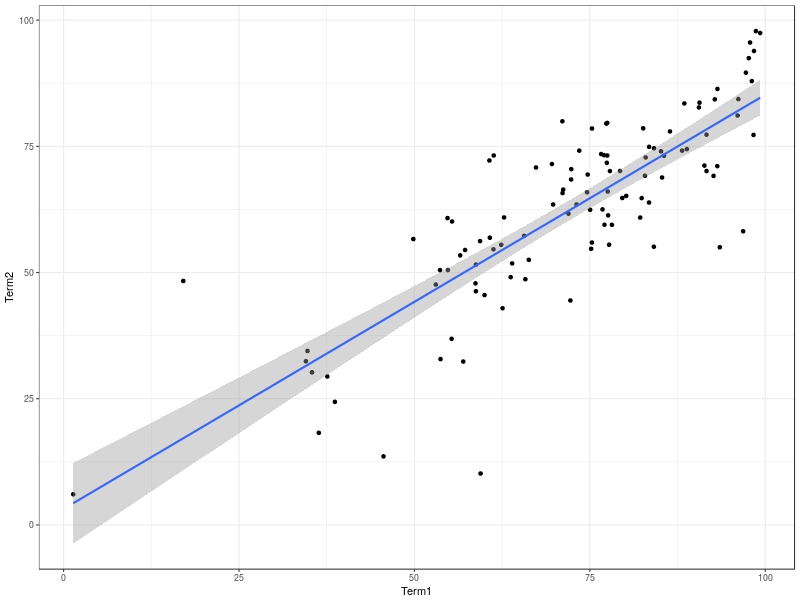
I’ve asked R to draw the regression line in the above picture; a straight line fit seems reasonable based on the plot. What are the statistics of that line?
R> summary(lm(Term2~Term1, data=d))
Call:
lm(formula = Term2 ~ Term1, data = d)
Residuals:
Min 1Q Median 3Q Max
-41.752 -6.032 1.138 6.107 31.155
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 3.18414 4.09773 0.777 0.439
Term1 0.82056 0.05485 14.961 <2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 10.46 on 107 degrees of freedom
(32 observations deleted due to missingness)
Multiple R-squared: 0.6766, Adjusted R-squared: 0.6736
F-statistic: 223.8 on 1 and 107 DF, p-value: < 2.2e-16
Looking at the summary above, we have a strong positive relationship between term 1 and term 2 marks. The intercept is approximately zero (if you got no marks in term 1, you should expect no marks in term 2), and the slope is less than one: on average, each mark a student got in term 1 tended to convert to 0.8 marks in term 2 – this is plausibly explained by the material being slightly harder in term 2, and by the fact that some of the assessments were more explicitly designed to allow finer discrimination at the top end – marks in the 90s. (A note for international readers: in the UK system, the pass mark is 40%, excellent work is typically awarded a mark in the 70% range – marks of 90% should be reserved for exceptional work). The average case is, however, only that: there was significant variation from that average line, and indeed (looking at the quartiles) over 50% of the cohort was more than half a degree class (5 percentage points) away from their term 2 mark as “predicted” from their mark for term 1.
All of this seems reasonable, and it was a privilege to work with this cohort of students, and to present the sum of their interactions on this course to the audience I had. I got the largest round of applause, I think, for revealing that as part of the peer-assessment I had required that students run each others’ code. I also had to present some of the context for the work; not only because this was an international gathering, with people in various university systems and from industry, but also because of the large-scale disruption caused by industrial action over the Universities Superannuation Scheme (the collective, defined benefit pension fund for academics at about 68 Universities and ~300 other bodies associated with Higher Education). Perhaps most gratifyingly, students were able to continue learning despite being deprived of their tuition for three consecutive weeks; judging by their performance on the various assessments so far,
And now? The students will sit an exam, after which I and colleagues will look in detail at those results and the relationship with the students’ coursework marks (as I did last year). I will continue developing this material (my board for this module currently lists 33 todo items), and adapt it for next year and for new cohorts. And maybe you will join me? The Computing department at Goldsmiths is hiring lecturers and senior lecturers to come and participate in research, scholarship and teaching in computing: a lecturer in creative computing, a lecturer in computer games, a lecturer in data science, a lecturer in physical and creative computing, a lecturer in computer science and a senior lecturer in computer science. Anyone reading this is welcome to contact me to find out more!
A few weeks ago, I attended the 2018 European Lisp Symposium.
If you were at the 2017 iteration, you might (as I do) have been left with an abiding image of greyness. That was not at all to fault the location (Brussels) or the organization (co-located with ) of the symposium; however, the weather was unkind, and that didn't help with my own personal low-energy mood at the time.
This year, the event was organized
by Ravenpack in Marbella. And the first
thing that I noticed on landing was the warmth. (Perhaps the only
“perk” of low-cost airlines is that it is most likely that one will
disembark on to terra firma rather than a passenger boarding bridge.
And after quite a miserable winter in the UK, the warmth and the
sunshine at the bus stop, while waiting for the bus from Malagá
airport to Marbella, was very welcome indeed. The sense of community
was strong too; while waiting for the bus, I hopped on to
#lisp IRC and Nic Hafner volunteered to meet me at the Marbella bus
station and walk with me to my hotel; we ended up going for drinks at
a beachside bar that evening with Dimitri Fontaine, Christian
Schafmeister, Mikhail Raskin and others – and while we were sitting
there, enjoying the setting, I saw other faces I recognised walking
past along the beach promenade.
The setting for the conference itself, the Centro Cultural Cortijo de Miraflores, was charming. We had the use of a room, just about big enough for the 90ish delegates; the centre is the seat of the Marbella Historical Archives, and our room was next to the olive oil exhibition.

We also had an inside courtyard for the breaks; sun, shade, water and
coffee were available in equal measure, and there was space for good
conversations – I spoke with many people, and it was great to catch up
and reminisce with old friends, and to discuss the finer points of
language implementation and release management with new ones. (I
continue to maintain that the SBCL time-boxed monthly release cadence
of master, initiated by Bill Newman way back in the SBCL 0.7 days in
2002 [!], has two distinct advantages, for our situation, compared
with other possible choices, and I said so more than once over
coffee.)
The formal programme, curated by Dave Cooper, was great too. Zach's written about his highlights; I enjoyed hearing Jim Newton's latest on being smarter about typecase, and Robert Smith's presentation about quantum computing, including a walkthrough of a quantum computing simulator. As well as quantum computing, application areas mentioned in talks this year included computational chemistry, data parallel processing, pedagogy, fluid dynamics, architecture, sentiment analysis and enterprise resource planning – and there were some implementation talks in there too, not least from R. “it’s part of the brand” Matthew Emerson, who gave a paean to Clozure Common Lisp. Highly non-scientific SBCL user feedback from ELS presenters: most of the speakers with CL-related talks or applications at least mentioned SBCL; most of those mentions by speaker were complimentary, but it's possible that most by raw count referred to bugs – solely due to Didier Verna's presentation about method combinations (more on this in a future blog post).
Overall, I found this year's event energising. I couldn't be there any earlier than the Sunday evening, nor could I stay beyond Wednesday morning, so I missed at least the organized social event, but the two days I had were full and stress-free (even when chairing sessions and for my own talk). The local organization was excellent; Andrew Lawson, Nick Levine and our hosts at the foundation did us proud; we had a great conference dinner, and the general location was marvellous.
Next year's event will once again be co-located with <Programming>, this time in Genova (sunny!) on 1st-2nd April 2019. Put it in your calendar now!
Another term, another cycle of Algorithms & Data Structures.
This year I am teaching the entire two-term course by myself, compared with last academic year when I co-taught with another member of staff. The change brings with it different challenges; notably that I am directly responsible for more content. Or in this case, more multiple-choice quizzes!
This term, the students have been given nine multiple-choice quizzes, of which four are new content and five are revisions of last year's quizzes. The revisions are mostly to add more variety to particular question types – finding axes of generalization that I hadn't exploited last time – and more (and more punishing) distractor answers, so that students cannot game the system too easily.
Some of this is my own adaptation to behaviours I see in the student body; for example, one behaviour I started seeing this year was the habit of selecting all the answers from a multiple-answer multiple-choice question. This was probably a reaction itself to the configuration of the quiz not telling the students the right answer after the attempt, but merely whether they had got it right or wrong; the behaviour of the quiz engine (the Moodle quiz activity) was for each selected answer to indicate the correctness status, and so students were exploiting this to see the right answers. This was not in itself a problem – there were enough questions that in the student's next attempts at the quiz they were unlikely to see the same questions again – but it was being used as a substitute for actually thinking and working at the problem, and so this was a behaviour that I wanted to discourage. The next quiz, therefore, I adapted so that it had many single-answer multiple choice with many more distractor answers than usual: seven or eight, rather than the usual three or so. (I do not know whether the message got through.)
The new quizzes address some weaknesses I saw in the student body of knowledge last year, and indeed have seen in previous years too: a general lack of a robust mental model (or possibly “notional machine” of computation. To try to address this, I taught a specific dialect of pseudocode in the introductory lecture (nothing particularly esoteric; in fact, essentially what is provided by the algorithmicx LaTeX package). I then also wrote a small interpreter in emacs lisp for that pseudocode language (with a s-expression surface syntax, of course) and a pretty-printer from s-expressions to HTML, so that I could randomly generate blocks of pseudocode and ask students questions about them: starting with the basics, with sequences of expressions, and introducing conditionals, loops, nested loops, and loops with break.
The results of this quiz were revealing; at the start of the cycle, many students were unable to answer questions about loops at all – perhaps unsurprising as the complete description of the loop syntax was only given to the students in the second lecture. Even those who had intuited the meaning of the loop form that I was using had difficulty with nested loops, and this difficulty remained evident all the way to the end of the quiz period. (By way of comparison, students were able to deal with quite complicated chains of conditionals with not much more difficulty than straight-line pseudocode.) It will be very interesting to see whether the reforms and extensions we have put in place to our first-year curriculum will make a difference to this particular task next year.
Of course, once I had the beginnings of a pseudocode interpreter and pretty-printer, I then got to use it elsewhere, to the point that it has now grown (almost) enough functionality to warrant a static analyser and compiler. I'm resisting, because fundamentally it's about generating questions for multiple-choice quizzes, not about being a language for doing anything else with – but with an even fuller model for the computation, I could make something akin to Paul F. Dietz' Common Lisp random tester (still active after 15 years) which would probably have helped me spot a mistake I made when generating multiple-choice answers to questions about recursive algorithms, of the form “which of the following expressions replaces X in order to make this function return the sum of its two arguments?”.
As well as the quizzes, the students have done six automatically-marked lab exercises and one technical peer-assessment. My direct involvement in assessment after setting all of these exercises has been limited to checking that the results of the peer-assessment are reasonable, by examining cases with outliers at a rate of maybe 6 minutes per student. Indirect involvement includes delivering lectures, answering questions face-to-face and on the forum, system administration, and writing code that writes code that writes summary feedback reports; this is probably a higher-value use of my time for the students than individualized marking; in that time, the students have received, on average: right-or-wrong judgments on 330 quiz questions (many of which have more than one possible right answer); 45 individual judgments on a moderately open algorithmic task; 50 marks and feedback on programming tasks; and a gentle helping of encouragement and sarcasm, in approximately equal measure, from me.
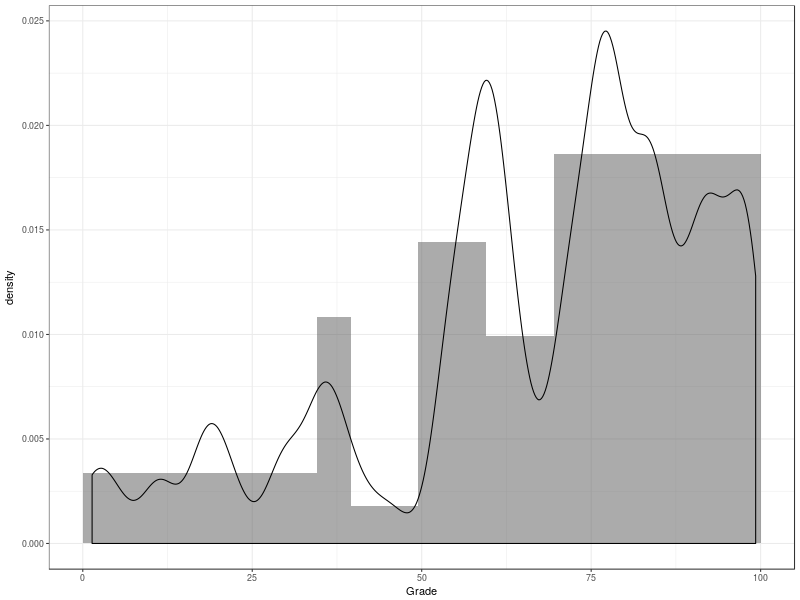
The coursework marks are encouraging; there are a cluster of students at the top, and while the lower tail is disappointingly substantial it is artificially enhanced by a number of students who have (for whatever reason) dropped out. Limiting the analysis to those students who missed at most one assessment gives a more pleasing distribution; almost no-one who attempted everything received a failing mark, though I should temper my satisfaction with that by saying that I need to be careful that I'm not simply giving credit for being able to show up. (There are also some marks from this picture in the middle range, 50-70, which are withheld while allegations of plagiarism and/or collusion are resolved.)
And now, as I write, it is the last working day before term starts
again, when the students return to find this term's lovingly
prepared hastily assembled activities. Onward!
I released sbcl-1.4.3 just before the new year.
Mostly this blog post is to remind me that I need to improve the release script:
The script assumes that I build on x86-64. That is usually true, but
this month there's a problem with building on my release build host,
which is a squeeze-era VM:
the new immobile-space support on x86-64 uses a synchonization builtin
(__atomic_load())
that wasn't supported in gcc-4.4, and I didn't have time to
investigate and test which of
the
__sync_ builtins is
an acceptable replacement before vanishing off the internet for a
couple of days. Probably:
hint = __sync_fetch_and_add(&page_hints[hint_index], 0);
Immobile space isn't (yet) supported on 32-bit x86. This meant that after shuffling some gpg keys around, I could do most of the release process on a 32-bit installation; the hard-coding of the architecture meant that I had to do some bits manually, so be more than usually suspicious when checking gnupg signatures.
Hopefully I'll arrange to fix some of this before the end of this month. (Testing the release script is a little tricky.)
Possible alternative title: I’m on a train!
In particular, I’m on the train heading to the European Lisp Symposium, and for the first time since December I don’t have a criticially urgent piece of teaching to construct. (For the last term, I’ve been under the cosh of attempting to teach Algorithms & Data Structures to a class, having never learnt Algorithms & Data Structures formally, let along properly, myself).
I have been giving the students some structure to help them in their learning by constructing multiple-choice quizzes. “But multiple-choice quizzes are easy!”, I hear you cry! Well, they might be in general, but these quizzes were designed to probe some understanding, and to help students recognize what they did not know; of the ten quizzes I ran this term, several had a period where the modal mark in the quiz was zero. (The students were allowed take the quizzes more than once; the idea behind that being that they can learn from their mistakes and improve their score; the score is correlated to a mark in some minor way to act as a tiny carrot-bite of motivation; this means I have to write lots of questions so that multiple attempts aren’t merely an exercise in memory or screenshot navigation).
The last time I was on a train, a few weeks ago, I was travelling to and from Warwick to sing Haydn’s Nelson Mass (“Missa in angustiis”; troubled times, indeed), and had to write a quiz on numbers. I’d already decided that I would show the students the clever Karatsuba trick for big integer multiplication, and I wanted to write some questions to see if they’d understood it, or at least could apply some of the results of it.
Standard multiplication as learnt in school is, fairly clearly, an Ω(d2) algorithm. My children learn to multiply using the “grid method”, where: each digit value of the number is written out along the edges of a table; the cells of the table are the products of the digit values; and the result is found by adding the cells together. Something like:
400 20 7
300 120000 6000 2100
90 36000 1800 630
3 1200 60 21
for 427×393 = 167811. Similar diagrammatic ways of multiplying (like [link]) duplicate this table structure, and traditional long multiplication or even the online multiplication trick where you can basically do everything in your head all multiply each digit of one of the multiplicands with each digit of the other.
But wait! This is an Algorithms & Data Structures class, so there must be some recursive way of decomposing the problem into smaller problems; divide-and-conquer is classic fodder for Computer Scientists. So, write a×b as (ahi×2k+alo)×(bhi×2k+blo), multiply out the brackets, and hi and lo and behold we have ahi×bhi×22k+(ahi×blo+alo×bhi)×2k+alo×blo, and we’ve turned our big multiplication into four multiplications of half the size, with some additional simpler work to combine the results, and big-O dear! that’s still quadratic in the number of digits to multiply. Surely there is a better way?
Yes there is. Karatsuba multiplication is a better (asymptotically at least) divide-and-conquer algorithm. It gets its efficiency from a clever observation[1]: that middle term in the expansion is expensive, and in fact we can compute it more cheaply. We have to calculate chi=ahi×bhi and clo=alo×blo, there’s no getting around that, but to get the cross term we can compute (ahi+alo)×(bhi+blo) and subtract off chi and clo: and that’s then one multiply for the result of two. With that trick, Karatsuba multiplication lets us turn our big multiplication into three multiplications of half the size, and that eventaully boils down to an algorithm with complexity Θ(d1.58) or thereabouts. Hooray!
Some of the questions I was writing for the quiz were for the students to compute the complexity of variants of Karatsuba’s trick: generalize the trick to cross-terms when the numbers are divided into thirds rather than halves, or quarters, and so on. You can multiply numbers by doing six multiplies of one-third the size, or ten multiplies of one-quarter the size, or... wait a minute! Those generalizations of Karatsuba’s trick are worse, not better! That was completely counter to my intuition that a generalization of Karatsuba’s trick should be asymptotically better, and that there was probably some sense in which the limit of doing divide-bigly-and-conquer-muchly would turn into an equivalent of FFT-based multiplication with Θ(d×log(d)) complexity. But this generalization was pulling me back towards Θ(d2)! What was I doing wrong?
Well what I was doing wrong was applying the wrong generalization. I don’t feel too much shame; it appears that Karatsuba did the same. If you’re Toom or Cook, you probably see straight away that the right generalization is not to be clever about how to calculate cross terms, but to be clever about how to multiply polynomials: treat the divided numbers as polynomials in 2k, and use the fact that you need one more value than the polynomial’s degree to determine all its coefficients. This gets you a product in five multiplications of one-third the size, or seven multiplications of one-quarter, and this is much better and fit with my intuition as to what the result should be. (I decided that the students could do without being explicitly taught about all this).
Meanwhile, here I am on my train journey of relative freedom, and I thought it might be interesting to see whether and where there was any benefit to implement Karatsuba multiplication in SBCL. (This isn’t a pedagogy blog post, or an Algorithms & Data Structures blog post, after all; I’m on my way to a Lisp conference!). I had a go, and have a half-baked implementation: enough to give an idea. It only works on positive bignums, and bails if the numbers aren’t of similar enough sizes; on the other hand, it is substantially consier than it needs to be, and there’s probably still some room for micro-optimization. The results?
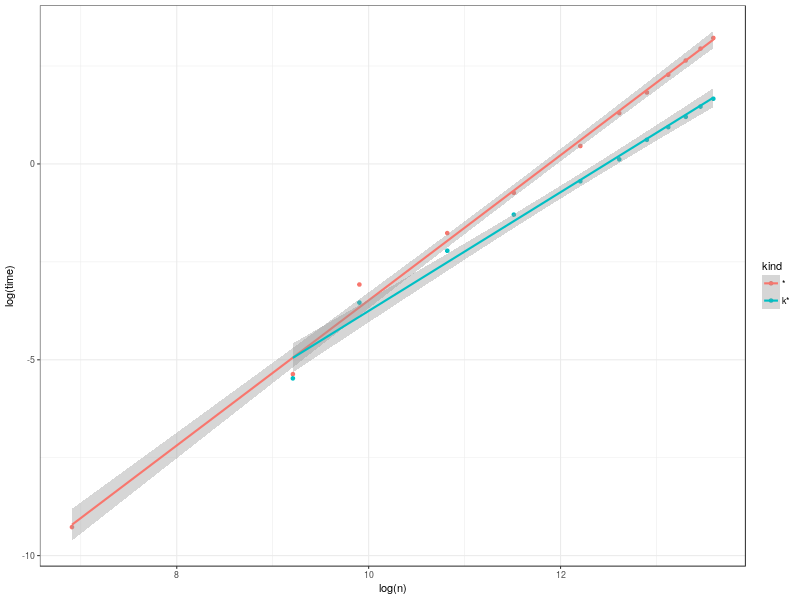
The slopes on the built-in and Karatsuba mulitply (according to the linear model fit) are 1.85±0.04 and 1.52±0.1 respectively, so even million-(binary)-digit bignums aren’t clearly in the asymptotic régimes for the two multiplication methods: but at that size (and even at substantially smaller sizes, though not quite yet at Juho’s 1000 bits) my simple Karatsuba implementation is clearly faster than the built-in multiply. I should mention that at least part of the reason that I have even heard of Karatsuba multiplication is Raymond Toy’s implementation of it in CMUCL.
Does anyone out there use SBCL for million-digit multiplications?
I’m going to the European Lisp Symposium this year! In fact, I have to catch a train in two and a half hours, so I should start thinking about packing.
I don’t have a paper to present, or indeed any agenda beyond catching up with old and new friends and having a little bit of space to think about what might be fun to try. If you’re there and you want to make suggestions, or just tell me what you’re up to: I’d love to hear. (And if you’re not there: bad luck, and see you another time!)
I’m not going to the European Lisp Symposium this year.
It’s a shame, because this is the first one I’ve missed; even in the height of the confusion of having two jobs, I managed to make it to Hamburg and Zadar. But organizing ELS2015 took a lot out of me, and it feels like it’s been relentless ever since; while it would be lovely to spend two days in Krakow to recharge my batteries and just listen to the good stuff that is going on, I can’t quite spare the time or manage the complexity.
Some of the recent complexity: following one of those “two jobs” link might give a slightly surprising result. Yes, Teclo Networks AG was acquired by Sandvine, Inc. This involved some fairly intricate and delicate negotiations, sucking up time and energy; some minor residual issues aside, I think things are done and dusted, and it’s as positive an outcome for all as could be expected.
There have also been a number of sadder outcomes recently; others have written about David MacKay’s recent death; I had the privilege to be in his lecture course while he was writing Information Theory, Inference, and Learning Algorithms, and I can trace the influence of both the course material and the lecturing style on my thought and practice. I (along with many others) admire his book about energy and humanity; it is beautifully clear, and starts from the facts and argues from those. “Please don’t get me wrong: I’m not trying to be pro-nuclear. I’m just pro-arithmetic.” – a rallying cry for advocates of rationality. I will also remember David cheefully agreeing to play the viola for the Jesus College Music Society when some preposterous number of independent viola parts were needed (my fallible memory says “Brandenburg 3”). David’s last interview is available to view; iPlayer-enabled listeners can hear Alan Blackwell’s (computer scientist and double-bassist) tribute on BBC Radio 4’s Last Word.
So with regret, I’m not travelling to Krakow this year; I will do my best to make the 10th European Lisp Symposium (how could I miss a nice round-numbered edition?), and in the meantime I’ll raise a glass of Croatian Maraschino, courtesy of my time in Zadar, to the success of ELS 2016.
There’s an awkward truth that perhaps isn’t as well known as it ought to be about academic careers: an oversupply of qualified, motivated candidates chasing an extremely limited supply of academic jobs. Simplifying somewhat, the problem is: if one tenured professor (or “lecturer” as we call them in the UK) is primarily responsible for fifteen PhDs over their career, then fourteen of those newly-minted doctors will not get permanent jobs in academia.
That wouldn’t be a problem if the career aspirations of people studying for doctorates were in line with the statistics – if about one in ten to one in twenty PhD candidates wanted a job in academia, then there would be minimal disappointment. However, that isn’t the case; many more doctoral students have the ambition and indeed the belief to go on and have an academic career: and when belief meets reality, sometimes things break. Even when they don’t, the oversupply of idealistic, qualified and motivated candidates leads to distortions, such as a large number of underpaid sessional teaching staff, assisting in the delivery of courses to ever larger cohorts of students (see also). The sector hasn’t sunk as low as the “unpaid internship” seen in other oversupplied careers (games, journalism, fashion) – though it has come close, and there are some zero-hour contract horror stories out there, as well as the nigh-on-exploitative short-term postdocs that are also part of the pyramid.
All this is a somewhat depressing way to set the scene for our way of redressing the balance: Goldsmiths Computing is hiring to fill a number of positions. Some of the positions are traditional lecturer jobs – fixed-term and permanent – and while they’re good openings, and I look forward to meeting candidates and working with whoever is successful, they’re not what’s most interesting here. We have also allocated funds for a number of post-doctoral teaching and research fellowships: three year posts where, in exchange for helping out with our teaching, the fellows will be able to pursue their own research agenda, working in collaboration with (but not under the direction of) established members of staff. I think this is a hugely positive move, and a real opportunity for anyone interesting in the particular kinds of areas of Computing that we have strengths in at Goldsmiths: Games and Graphics, Music and Art Computing, Data and Social Computing, Human-Computer Interaction and AI, Robotics and Cognition. (And if applicants were to want to work with me on projects in Music Informatics or even involving some programming language work, so much the better!)
The complete list of positions we’re hoping to fill (apply by searching for the “Computing” Department in this search form) is:
- Lecturer in Computational Art – 0.5FTE, 3 year fixed-term
- Lecturer in Computer Science – full-time, 3 year fixed-term
- Lecturer in Computer Science – 0.5FTE, 3 year fixed-term
- Lecturer in Games and Graphics – full-time, open-ended
- Lecturer in Games Art – 0.5FTE, open-ended
- Lecturer in Physical Computing – full-time, open-ended
- Post-doctoral Teaching and Research Fellow – full-time, 3 year fixed-term
The deadline for applications for most of these posts is Monday 8th June, so get applying!
Oh boy.
It turns out that organizing a conference is a lot of work. Who’d
have thought? And it’s a lot of work even after accounting for the
benefits of an institutional
Conference Services
division, who managed things that only crossed my mind very late:
signage, extra supplies for college catering outlets – the kinds of
things that are almost unnoticeable if they’re present, but whose
absence would cause real problems. Thanks to Julian Padget, who ran
the programme, and Didier Verna, who handled backend-financials and
the website; but even after all that there were still a good number of
things I didn’t manage to delegate – visa invitation letters, requests
for sponsorship, printing proceedings, attempting to find a
last-minute solution for recording talks after being reminded of it on
the Internet somewhere... I’m sure there is more (e.g.
overly-restrictive campus WiFi, blocking outbound ssh and
TLS-enabled IMAP) but it’s beginning to fade into a bit of a blur.
(An enormous “thank you” to
Richard Lewis for stepping in to
handle recording the talks as best he could at very short notice).
And the badges! People said nice things about the badges on twitter, but... I used largely the same code for the ILC held in Cambridge in 2007, and the comment passed back to me then was that while the badges were clearly going to become collectors’ items, they failed in the primary purpose of a badge at a technical conference, which is to give to the introvert with poor facial recognition some kind of clue who they are talking to: the font size for the name was too small. Inevitably, I got round to doing the badges at the last minute, and between finding the code to generate PDFs of badges (I’d lost my local copy, but the Internet had one), finding a supplier for double-sided sheets of 10 85x54mm business cards, and fighting with the office printer (which insisted it had run out of toner) the thought of modifying the code beyond the strictly necessary didn’t cross my mind. Since I asked for feedback in the closing session, it was completely fair for a couple of delegates to say that the badges could have been better in this respect, so in partial mitigation I offer a slightly cleaned-up and adjusted version of the badge code with the same basic design but larger names: here you go (sample output). (Another obvious improvement suggested to me at dinner on Tuesday: print a list of delegate names and affiliations and pin it up on a wall somewhere).
My experience of the conference is likely to be atypical – being the responsible adult, I did have to stay awake at all times, and do some of the necessary behind-the-scenes stuff while the event was going on. But I did get to participate; I listened to most of most of the talks, with particular highlights for me being Breanndán Ó Nualláin’s talk about a DSL for graph algorithms, Martin Cracauer’s dense and technical discussion of conservative garbage collection, and the demo session on Tuesday afternoon: three distinct demos in three different areas, each both well-delivered and with exciting content. Those highlights were merely the stand-out moments for me; the rest of the programme was pretty good, too, and it looked like there were some good conversations happening in the breaks, over lunch, and at the banquet on Monday evening. We ended up with 90 registrations all told, with people travelling in from 18 other countries; the delegate with the shortest distance to travel lived 500m from Goldsmiths; the furthest came from 9500km away.
The proceedings are now available for free download from the conference website; some speakers have begun putting up their talk materials, and in the next few weeks we’ll try to collect as much of that as we can, along with getting release permissions from the speakers to edit and publish the video recordings. At some point there will be a financial reckoning, too; Goldsmiths has delivered a number of services on trust, while ELSAA has collected registration fees in order to pay for those services – one of my next actions is to figure out the bureaucracy to enable these two organizations to talk to each other. Of course, Goldsmiths charges in pounds, while ELSAA collected fees in euros, and there’s also the small matter of cross-border sales tax to wrap my head around... it’s exciting being a currency speculator!
In summary, things went well – at least judging by the things people said to my face. I’m not quite going to say “A+ would organize again”, because it is a lot of work – but organizing it once is fine, and a price worth paying to help sustain and to contribute to the communication between multiple different Lisp communities. It would be nice to do some Lisp programming myself some day: some of the stuff that you can do with it is apparently quite neat!
This year, I have had the dubious pleasure of being the Local
Organizer for the
European Lisp Symposium 2015,
which is now exactly one month away; in 31 days, hordes of people will
be descending on South East London
 to listen to presentations, give lightning talks and engage in general
discussions about all things Lisp – the programme isn’t quite
finalized, but expect Racket, Clojure, elisp and Common Lisp to be
represented, as well as more... minority interests, such as C++.
to listen to presentations, give lightning talks and engage in general
discussions about all things Lisp – the programme isn’t quite
finalized, but expect Racket, Clojure, elisp and Common Lisp to be
represented, as well as more... minority interests, such as C++.
Registration is open! In fact, for the next nine days (until 29th March) the registration fee is set at the absurdly low price of €120 (€60 for students) for two days of talks, tutorials, demos, coffee, pastries, biscuits, convivial discussion and a conference dinner. I look forward to welcoming old and new friends alike to Goldsmiths.
The AHRC-funded research project that I am a part of, Transforming Musicology, is recruiting a developer for a short-term contract, primarily to work with me on database systems for multimedia (primarily audio) content. The goal for that primary part of the contract is to take some existing work on audio feature extraction and probabilistic nearest-neighbour search indexing, and to develop a means for specialist users (e.g. musicologists, librarians, archivists, musicians) to access the functionality without needing to be experts in the database domain. This of course will involve thinking about user interfaces, but also about distributed computation, separation of data and query location, and so on.
The funding is for six months of programmer time. I would have no objection to someone working for six months in a concentrated block of time; I would also have no objection to stretching the funding out over a longer period of calendar time: it might well provide more time for reflection and a better outcome in the end. I would expect the development activities to be exploratory as well as derived from a specification; to span between the systems and the interface layer; to be somewhat polyglot (we have a C++ library, bindings in Python, Common Lisp and Haskell, and prototype Javascript and Emacs front-ends – no applicant is required to be fluent in all of these!)
There are some potentially fun opportunities during the course of the contract, not least working with the rest of the Transforming Musicology team. The post is based at Goldsmiths, and locally we have some people working on Systems for Early Music, on Musicology and Social Networking, and on Musical Memory; the Goldsmiths contribution is part of a wider effort, with partners based at Oxford working on Wagnerian Leitmotif and on a Semantic Infrastructure, at Queen Mary working on mid-level representations of music, and in Lancaster coordinating multiple smaller projects. As well as these opportunities for collaboration, there are a number of events coming up: firstly, the team would hope to have a significant presence at the conference of the International Society for Music Information Retrieval, which will be held in Málaga in October. We don’t yet know what we will be submitting there (let alone what will be accepted!) but there should be an opportunity to travel there, all being well. In July we’ll be participating in the Digital Humanities at Oxford Summer School, leading a week-long programme of workshops and lectures on digital methods for musicology. Also, in November of 2014, we also participated in the AHRC’s “Being Human” festival, with a crazy effort to monitor participants’ physiological responses to Wagner opera; there’s every possibility that we will be invited to contribute to a similar event this year. And there are other, similar projects in London with whom we have friendly relations, not least the Digital Music Lab project at City University and the EU-funded PRAISE project at Goldsmiths.
Sound interesting? Want to apply? There’s a more formal job advert on the project site, while the “person specification” and other application-related materials is with Goldsmiths HR. The closing date for applications is the 27th March; we’d hope to interview shortly after that, and to have the developer working with us from some time in May or June. Please apply!
A brief retrospective, partly brought to you by grep:
- CATS credits earnt: 30 (15 + 7.5 + 7.5) at level 7
- crosswords solved: >=40
- words blogged: 75k
- words blogged, excluding crosswords: 50k
- SBCL releases made: 12 (latest today!)
- functioning ARM boards sitting on my desk: 3 (number doing anything actually useful, beyond SBCL builds: 0 so far, working on it)
- emacs packages worked on: 2 (iplayer squeeze)
- public engagement events co-organized: 1
- ontological inconsistencies resolved: 1
- R packages made: 1 (University PR departments offended: not enough)
{kind=link}
Blogging’s been a broad success; slightly tailed off of late, what with
- Crawl Dungeon Sprint wins: 2 (The Pits, Thunderdome: both GrFi)
so there’s an obvious New Year’s Resolution right there.
Happy New Year!
I think this might be my last blog entry on the subject of building SBCL for a while.
One of the premises behind SBCL as a separate entity from CMUCL, its parent, was to make the result of its build be independent of the compiler used to build it. To a world where separate compilation is the norm, the very idea that building some software should persistently modify the state of the compiler probably seems bizarre, but the Lisp world evolved in that way and Lisp environments (at least those written in themselves) developed build recipes where the steps to construct a new Lisp system from an old one and the source code would depend critically on internal details of both the old and the new one: substantial amounts of introspection on the build host were used to bootstrap the target, so if the details revealed by introspection were no longer valid for the new system, there would need to be some patching in the middle of the build process. (How would you know whether that was necessary? Typically, because the build would fail with a more-or-less – usually more – cryptic error.)
Enter SBCL, whose strategy is essentially to use the source files
first to build an SBCL!Compiler running in a host Common Lisp
implementation, and then to use that SBCL!Compiler to compile the
source files again to produce the target system. This requires some
contortions in the source files: we must write enough of the system in
portable Common Lisp so that an arbitrary host can execute
SBCL!Compiler to compile SBCL-flavoured sources (including the
standard headache-inducing (defun car (list) (car list)) and
similar, which works because SBCL!Compiler knows how to compile calls
to
car).
How much is “enough” of the system? Well, one answer might be when the build output actually works, at least to the point of running and executing some Lisp code. We got there about twelve years ago, when OpenMCL (as it was then called) compiled SBCL. And yet... how do we know there aren't odd differences that depend on the host compiler lurking, which will not obviously affect normal operation but will cause hard-to-debug trouble later? (In fact there were plenty of those, popping up at inopportune moments).
I’ve been working intermittently on dealing with this, by attempting to make the Common Lisp code that SBCL!Compiler is written in sufficiently portable that executing it on different implementations generates bitwise-identical output. Because then, and only then, can we be confident that we are not depending in some unforseen way on a particular implementation-specific detail; if output files are different, it might be a harmless divergence, for example a difference in ordering of steps where neither depends on the other, or it might in fact indicate a leak from the host environment into the target. Before this latest attack at the problem, I last worked on it seriously in 2009, getting most of the way there but with some problems remaining, as measured by the number of output files (out of some 330 or so) whose contents differed depending on which host Common Lisp implementation SBCL!Compiler was running on.
Over the last month, then, I have been slowly solving these problems, one by one. This has involved refining what is probably my second most useless skill, working out what SBCL fasl files are doing by looking at their contents in a text editor, and from that intuiting the differences in the implementations that give rise to the differences in the output files. The final pieces of the puzzle fell into place earlier this week, and the triumphant commit announces that as of Wednesday all 335 target source files get compiled identically by SBCL!Compiler, whether that is running under Clozure Common Lisp (32- or 64-bit versions), CLISP, or a different version of SBCL itself.
Oh but wait. There is another component to the build: as well as
SBCL!Compiler, we have SBCL!Loader, which is responsible for taking
those 335 output files and constructing from them a Lisp image file
which the platform executable can use to start a Lisp session.
(SBCL!Loader is maybe better known as “genesis”; but it is to
load
what SBCL!Compiler is to
compile-file).
And it was slightly disheartening to find that despite having 335
identical output files, the resulting cold-sbcl.core file differed
between builds on different host compilers, even after I had
remembered to discount the build fingerprint constructed to be
different for every build.
Fortunately, the actual problem that needed fixing was relatively
small: a call to
maphash,
which (understandably) makes no guarantees about ordering, was used to
affect the Lisp image data directly. I then spent a certain amount of
time being thoroughly confused, having managed to construct for myself
a Lisp image where the following forms executed with ... odd results:
(loop for x being the external-symbols of "CL" count 1)
; => 1032
(length (delete-duplicates (loop for x being the external-symbols of "CL" collect x)))
; => 978
(shades of times gone by). Eventually I realised that
(unless (member (package-name package) '("COMMON-LISP" "KEYWORD" :test #'string=))
...)
was not the same as
(unless (member (package-name package) '("COMMON-LISP" "KEYWORD") :test #'string=)
...)
and all was well again, and as of
this commit
the cold-sbcl.core output file is identical no matter the build
host.
It might be interesting to survey the various implementation-specific behaviours that we have run into during the process of making this build completely repeatable. The following is a probably non-exhaustive list – it has been twelve years, after all – but maybe is some food for thought, or (if you have a particularly demonic turn of mind) an ingredients list for a maximally-irritating CL implementation...
- Perhaps most obviously, various constants are
implementation-defined. The ones which caused the most trouble were
undoubtably
most-positive-fixnumandmost-negative-fixnum– particularly since they could end up being used in ways where their presence wasn’t obvious. For example,(deftype fd () `(integer 0 ,most-positive-fixnum))has, in the SBCL build process, a subtly different meaning from(deftype fd () (and fixnum unsigned-byte))– in the second case, thefdtype will have the intended meaning in the target system, using the target’sfixnumrange, while in the first case we have no way of intercepting or translating the host’s value ofmost-positive-fixnum. Special mentions go toarray-dimension-limit, which caused Bill Newman to be cross on the Internet, and tointernal-time-units-per-second; I ended up tracking down one difference in output machine code from a leak of the host’s value of that constant into target code. - Similarly,
randomandsxhashquite justifiably differ between implementations. The practical upshot of that is that these functions can’t be used to implement a cache in SBCL!Compiler, because the access patterns and hence the patterns of cache hits and misses will be different depending on the host implementation. - As I’ve already mentioned,
maphashdoes not iterate over hash-table contents in a specified order, and in fact that order need not be deterministic; similarly,with-package-iteratorcan generate symbols in arbitrary orders, and set operations (intersection,set-differenceand friends) will return the set as a list whose elements are in an arbitrary order. Incautious use of these functions tended to give rise to harmless but sometimes hard-to-diagnose differences in output; the solution was typically to sort the iteration output before operating on any of it, to introduce determinism... - ... but it was possible to get that wrong in a harder-to-detect way,
because
sortisnot specified to be stable. In some implementations, it actually is a stable sort in some conditions, but for cases where it’s important to preserve an already-existing partial order,stable-sortis the tool for the job. - The language specification explicitly says that the initial contents
of uninitialized arrays are undefined. In most implementations, at
most times, executing
(make-array 8 :element-type (unsigned-byte 8))will give a zero-filled array, but there are circumstances in some implementations where the returned array will have arbitrary data. - Not only are some constants implementation-defined, but so also are
the effects of normal operation on some variables.
*gensym-counter*is affected by macroexpansion if the macro function callsgensym, and implementations are permitted to macroexpand macros an arbitrary number of times. That means that our use ofgensymneeds to be immune to whatever the host implementation’s macroexpansion and evaluation strategy is. - The object returned by
byteto represent a bitfield with size and position is implementation-defined. Implementations (variously) return bitmasks, conses, structures, vectors; host return values ofbytemust not be used during the execution of SBCL!Compiler. More subtly, the variousboole-related constants (boole-andand friends) also need special treatment; at one point, their host values were used when SBCL!Compiler compiled theboolefunction itself, and it so happens that CLISP and SBCL both represent the constants as integers between 0 and 15... but with a different mapping between operation and integer. - my last blog entry talked
about constant coalescing, and about printing of
(quote foo). In fact printing in general has been a pain, and there are still significant differences in interpretation or at least in implementation of pretty-printing: to the extent that at one point we had to minimize printing at all in order for the build to complete under some implementations. - there are a number of things which are implementation-defined but
have caused a certain amount of difficulty. Floating point in
general is a problem, not completely solved (SBCL will not build
correctly if its host doesn’t have distinct single- and double-float
types that are at least approximately IEEE754-compliant). Some
implementations lack denormalized numbers; some do not expose signed
zeros to the user; and some implementations compute
(log 2d0 10d0)more accurately than others, including SBCL itself, do. The behaviour of the host implementation on legal but dubious code is also potentially tricky: SBCL’s build treats fullwarnings as worthy of stopping, but some hosts emit full warnings for constructs that are tricky to write in other ways: for example to write portable code to handle multiple kinds of string, one might write(typecase string (simple-base-string ...) ((simple-array character (*)) ...)) (string ...))but some implementations emit fullwarnings if a clause in atypecaseis completely shadowed by other clauses, and ifbase-charandcharacterare identical in that implementation thetypecaseabove will signal.
There were probably other, more minor differences between implementations, but the above list gives a flavour of the things that needed doing in order to get to this point, where we have some assurance that our code is behaving as intended. And all of this is a month ahead of my self-imposed deadline of SBCL’s 15th birthday: SBCL was announced to the world on December 14th, 1999. (I’m hoping to be able to put on an sbcl15 workshop in conjunction with the European Lisp Symposium around April 20th/21st/22nd – if that sounds interesting, please pencil the dates in the diary and let me know...)
It’s been nearly fifteen years, and SBCL still can’t be reliably built by other Lisp compilers.
Of course, other peoples’ definition of “reliably” might differ. We
did achieve successful building under unrelated Lisp compilers
twelve years ago;
there were a couple of nasty bugs along the way, found both before and
after that triumphant announcement, but at least with a set of
compilers whose interpretation of the standard was sufficiently
similar to SBCL’s own, and with certain non-mandated but expected
features (such as the type (array (unsigned-byte 8) (*)) being
distinct from simple-vector, and single-float being distinct from
double-float), SBCL achieved its aim of being buildable on a system
without an SBCL binary installed (indeed, using CLISP or XCL as a
build host, SBCL could in theory be bootstrapped starting with only
gcc).
For true “reliability”, though, we should not be depending on any
particular implementation-defined features other than ones we actually
require – or if we are, then the presence or absence of them should
not cause a visible difference in the resulting SBCL. The most common
kind of leak from the host lisp to the SBCL binary was the host’s
value of
most-positive-fixnum
influencing the target, causing problems from documentation errors all
the way up to type errors in the assembler. Those leaks were mostly
plugged a while ago, though they do recur every so often; there are
other problems, and over the last week I spent some time tracking down
three of them.
The first: if you’ve ever done (apropos "PRINT") or something
similar at the SBCL prompt, you might wonder at the existence of
functions named something like
SB-VM::|CACHED-FUN--PINSRB[(EXT-2BYTE-XMM-REG/MEM ((PREFIX (QUOTE (102))) (OP1 (QUOTE (58))) (OP2 (QUOTE (32))) (IMM NIL TYPE (QUOTE IMM-BYTE))) (QUOTE (NAME TAB REG , REG/MEM ...)))]-EXT-2BYTE-XMM-REG/MEM-PRINTER|.
What is going on there? Well, these functions are a part of the
disassembler machinery; they are responsible for taking a certain
amount of the machine code stream and generating a printed
representation of the corresponding assembly: in this case, for the
PINSRB
instruction. Ah, but (in most instruction sets) related instructions
share a fair amount of structure, and decoding and printing a PINSRD
instruction is basically the same as for PINSRB, with just one
#x20 changed to a #x22 – in both cases we want the name of the
instruction, then a tab, then the destination register, a comma, the
source, another comma, and the offset in the destination register. So
SBCL arranges to reuse the PINSRB instruction printer for PINSRD;
it maintains a cache of printer functions, looked up by printer
specification, and reuses them when appropriate. So far, so normal;
the ugly name above is the generated name for such a function,
constructed by interning a printed, string representation of some
useful information.
Hm, but wait. See those (QUOTE (58)) fragments inside the name?
They result from printing the list (quote (58)). Is there a
consensus on how to print that list? Note that
*print-pretty*
is bound to
nil
for this printing; prior experience has shown that there are strong
divergences between implementations, as well as long-standing
individual bugs, in pretty-printer support. So, what happens if I do
(write-to-string '(quote foo) :pretty nil)?
- SBCL:
"(QUOTE FOO)", unconditionally - CCL:
"'FOO"by default;"(QUOTE FOO)"ifccl:*print-abbreviate-quote*is set tonil - CLISP:
"'FOO", unconditionally (I read the.dcode with comments in half-German to establish this)
So, if SBCL was compiled using CLISP, the name of the same function in
the final image would be
SB-VM::|CACHED-FUN--PINSRB[(EXT-2BYTE-XMM-REG/MEM ((PREFIX '(102)) (OP1 '(58)) (OP2 '(32)) (IMM NIL TYPE 'IMM-BYTE)) '(NAME TAB REG , REG/MEM ...))]-EXT-2BYTE-XMM-REG/MEM-PRINTER|.
Which is shorter, and maybe marginally easier to read, but importantly
for my purposes is not bitwise-identical.
Thus, here we have a difference between host Common Lisp compilers
which leaks over into the final image, and it must be eliminated.
Fortunately, this was fairly straightforward to eliminate; those names
are never in fact used to find the function object, so generating a
unique name for functions based on a counter makes the generated
object file bitwise identical, no matter how the implementation prints
two-element lists beginning with quote.
The second host leak is also related to quote, and to our old friend
backquote – though not related in any way to the
new implementation. Consider this
apparently innocuous fragment, which is a simplified version of some
code to implement the :type option to
defstruct:
(macrolet ((def (name type n)
`(progn
(declaim (inline ,name (setf ,name)))
(defun ,name (thing)
(declare (type simple-vector thing))
(the ,type (elt thing ,n)))
(defun (setf ,name) (value thing)
(declare (type simple-vector thing))
(declare (type ,type value))
(setf (elt thing ,n) value)))))
(def foo fixnum 0)
(def bar string 1))
What’s the problem here? Well, the functions are declaimed to be
inline,
so SBCL records their source code. Their source code is generated by
a macroexpander, and so is made up of conses that are generated
programmatically (as opposed to freshly consed by the reader). That
source code is then stored as a literal object in an object file,
which means in practice that instructions for reconstructing a similar
object are dumped, to be executed when the object file is processed by
load.
Backquote
is a reader macro that expands into code that, when evaluated,
generates list structure with appropriate evaluation and splicing of
unquoted fragments. What does this mean in practice? Well, one
reasonable implementation of reading `(type ,type value) might
be:
(cons 'type (cons type '(value)))
and indeed you might (no guarantees) see something like that if you do
(macroexpand '`(type ,type value))
in the implementation of your choice. Similarly, reading `(setf
(elt thing ,n) value) will eventually generate code like
(cons 'setf (cons (cons 'elt (list 'thing n)) '(value)))
Now, what is “similar”? In this context, it has a technical definition: it relates two objects in possibly-unrelated Lisp images, such that they can be considered to be equivalent despite the fact that they can’t be compared:
similar adj. (of two objects) defined to be equivalent under the similarity relationship.
similarity n. a two-place conceptual equivalence predicate, which is independent of the Lisp image so that two objects in different Lisp images can be understood to be equivalent under this predicate. See Section 3.2.4 (Literal Objects in Compiled Files).
Following that link, we discover that similarity for
conses
is defined in the obvious way:
Two conses, S and C, are similar if the car of S is similar to the car of C, and the cdr of S is similar to the cdr of C.
and also that implementations have some obligations:
Objects containing circular references can be externalizable objects. The file compiler is required to preserve eqlness of substructures within a file.
and some freedom:
With the exception of symbols and packages, any two literal objects in code being processed by the file compiler may be coalesced if and only if they are similar [...]
Put this all together, and what do we have? That def macro above
generates code with similar literal objects: there are two instances
of '(value) in it. A host compiler may, or may not, choose to
coalesce those two literal '(value)s into a single literal object;
if it does, the inline expansion of foo (and bar) will have a
circular reference, which must be preserved, showing up as a
difference in the object files produced during the SBCL build. The
fix? It’s ugly, but portable: since we can’t stop an aggressive
compiler from coalescing constants which are similar but not
identical, we must make sure that any similar substructure is in fact
identical:
(macrolet ((def (name type n)
(let ((value '(value)))
`(progn
(declaim (inline ,name (setf ,name)))
(defun ,name (thing)
(declare (type simple-vector thing))
(the ,type (elt thing ,n)))
(defun (setf ,name) (value thing)
(declare (type simple-vector thing))
(declare (type ,type . ,value))
(setf (elt thing ,n) . ,value)))))
(def foo fixnum 0)
(def bar string 1))
Having dealt with a problem with
quote,
and a problem with
backquote,
what might the Universe serve up for my third problem? Naturally, it
would be a problem with a code walker. This code walker is
somewhat naïve, assuming as it does
that its body is made up of forms or tags; it is the assemble macro,
which is used implicitly in the definition of VOPs (reusable assembly
units); for example, like
(assemble ()
(move ptr object)
(zeroize count)
(inst cmp ptr nil-value)
(inst jmp :e DONE)
LOOP
(loadw ptr ptr cons-cdr-slot list-pointer-lowtag)
(inst add count (fixnumize 1))
(inst cmp ptr nil-value)
(inst jmp :e DONE)
(%test-lowtag ptr LOOP nil list-pointer-lowtag)
(error-call vop 'object-not-list-error ptr)
DONE))
which generates code to compute the length of a list. The expander
for assemble scans its body for any atoms, and generates binding
forms for those atoms to labels:
(let ((new-labels (append labels
(set-difference visible-labels inherited-labels))))
...
`(let (,@(mapcar (lambda (name) `(,name (gen-label))) new-labels))
...))
The problem with this, from a reproducibility point of view, is that
set-difference
(and the other set-related functions:
union,
intersection,
set-exclusive-or
and their n-destructive variants) do not return the sets with a
specified order – which is fine when the objects are truly treated as
sets, but in this case the LOOP and DONE label objects ended up in
different stack locations depending on the order of their binding.
Consequently the machine code for the function emitting code for
computing a list’s length – though not the machine code emitted by
that function – would vary depending on the host’s implementation of
set-difference.
The fix here was to sort the result of the set operations, knowing
that all the labels would be symbols and that they could be treated as
string designators.
And after all this is? We’re still not quite there: there are three to four files (out of 330 or so) which are not bitwise-identical for differing host compilers. I hope to be able to rectify this situation in time for SBCL’s 15th birthday...
One of SBCL’s Google Summer of Code students, Krzysztof Drewniak (no relation) just got to merge in his development efforts, giving SBCL a far more complete set of Unicode operations.
Given that this was the merge of three months’ out-of-tree work, it’s
not entirely surprising that there were some hiccups, and indeed we
spent some time
diagnosing and fixing
a 1000-fold slowdown in
char-downcase.
Touch wood, all seems mostly well, except that Jan Moringen reported
that, when building without the :sb-unicode feature (and hence
having a Lisp with 8-bit characters) one of the printer consistency
tests was resulting in an error.
Tracking this down was fun; it in fact had nothing in particular to do with the commit that first showed the symptom, but had been lying latent for a while and had simply never shown up in automated testing. I’ve expressed my admiration for the Common Lisp standard before, and I’ll do it again: both as a user of the language and as an implementor, I think the Common Lisp standard is a well-executed document. But that doesn’t stop it from having problems, and this is a neat one:
When a line break is inserted by any type of conditional newline, any blanks that immediately precede the conditional newline are omitted from the output and indentation is introduced at the beginning of the next line.
(from pprint-newline)
For the graphic standard characters, the character itself is always used for printing in #\ notation---even if the character also has a name[5].
(from CLHS 22.1.3.2)
Space is defined to be graphic.
(from CLHS glossary entry for ‘graphic’)
What do these three requirements together imply? Imagine printing the
list (#\a #\b #\c #\Space #\d #\e #\f) with a right-margin of 17:
(write-to-string '(#\a #\b #\c #\Space #\d #\e #\f) :pretty t :right-margin 17)
; => "(#\\a #\\b #\\c #\\
; #\\d #\\e #\\f)"
The #\Space character is defined to be graphic; therefore, it must
print as #\ rather than #\Space; if it happens to be printed just
before a conditional newline (such as, for example, generated by using
pprint-fill
to print a list), the pretty-printer will helpfully remove the space
character that has just been printed before inserting the newline.
This means that a #\Space character, printed at or near the right
margin, will be read back as a #\Newline character.
It’s interesting to see what other implementations do.
CLISP 2.49 in its default mode always prints
#\Space; in -ansi mode it prints #\ but preserves the space
even before a conditional newline. CCL
1.10 similarly preserves the space; there’s an explicit check in
output-line-and-setup-for-next for an “escaped” space (and a comment
that acknowledges that this is a heuristic that can be wrong in the
other direction). I’m not sure what the best fix for this is; it’s
fairly clear that the requirements on the printer aren’t totally
consistent. For SBCL, I have merged a one-line change that makes the
printer print using character names even for graphic characters, if
the
*print-readably*
printer control variable is true; it may not be ideal that print/read
round-tripping was broken in the normal case, but in the case where
it’s explicitly been asked for it is clearly wrong.
Since it seems still topical to talk about Lisp and
code-transformation macros, here’s another worked example – this time
inspired by the enthusiasm for the R
magrittr
package.
The basic idea behind the magrittr package is, as
Hadley said at EARL2014, to
convert from a form of code where arguments to the same function are
far apart to one where they’re essentially close together; the example
he presented was converting
arrange(
summarise
group_by(
filter(babynames, name == "Hadley"),
year),
total = sum(n)
desc(year))
to
b0 <- babynames
b1 <- filter(b0, name == "Hadley")
b2 <- group_by(b1, year)
b3 <- summarise(b2, total = sum(n))
b4 <- arrange(b3, desc(year))
only without the danger of mistyping one of the variable names along the way and failing to perform the computation that was intended.
R, as I have said before, is a Lisp-1 with weird syntax and wacky evaluation semantics. One of the things that ordinary user code can do is inspect the syntactic form of its arguments, before evaluating them. This means that when looking at a fragment of code such as
foo(bar(2,3), 4)
where a call-by-value language would first evaluate bar(2,3), then
call foo with two arguments (the value resulting from the
evaluation, and 4), R instead uses a form of call-by-need evaluation,
and also provides operators for inspecting the promise directly.
This means R users can do such horrible things as
foo <- function(x) {
tmp <- substitute(x)
sgn <- 1
while(class(tmp) == "(") {
tmp <- tmp[[2]]
sgn <- sgn * -1
}
sgn * eval.parent(tmp)
}
foo(3) # 3
foo((3)) # -3
foo(((3))) # 3
foo((((3)))) # -3 (isn’t this awesome? I did say “wacky”)
In the case of magrittr, the package authors have taken advantage of
this to invent some new syntax; the pipe operator %>% is charged
with inserting its first argument (its left-hand side, in normal
operation) as the first argument to the call of its second argument
(right-hand side). Hadley’s example is
babynames %>%
filter(name == "Hadley") %>%
group_by(year) %>%
summarise(total = sum(n)) %>%
arrange(desc(year))
and this is effective because the data flow in this case really is a
pipeline: there's a dataset, which needs filtering, then grouping,
then summarization, then sorting, and each operation works on the
result of the previous. This already needs to inspect the syntactic
form of the argument; an additional feature is recognizing the
presence of .s in the call, and placing the left-hand side value in
that argument position instead of as the first argument if it is
present.
In Common Lisp, there are some piping or chaining operators out there
(e.g. one
two
three (search for
ablock)
four
and probably many others), and they do well enough. However! They
mostly suffer from similar problems that we’ve seen before: doing code
transformations with not quite enough understanding of the semantics
of the code that they’re transforming; again, that’s fine for normal
use, but for didactic purposes let’s pretend that we really care
about this.
The -> macro from http://stackoverflow.com/a/11080068 is basically
the same as the magrittr %>% operator: it converts symbols in the
pipeline to function calls, and places the result of the previous
evaluation as the first argument of the current operator, except if a
$ is present in the arguments, in which case it replaces that.
(This version doesn’t support more than one $ in the argument list;
it would be a little bit of a pain to support that, needing a
temporary name, but it’s straightforward in principle).
Since the -> macro does its job, a code-walker implementation isn’t
strictly necessary: pure syntactic manipulation is good enough, and if
it’s used with just the code it expects, it will do it well. It is of
course possible to express what it does using a code-walker; we’ll fix
the multiple-$ ‘bug’ along the way, by explicitly introducing bindings
rather than replacements of symbols:
(defmacro -> (form &body body)
(labels ((find-$ (form env)
(sb-walker:walk-form form env
(lambda (f c e)
(cond
((eql f '$) (return-from find-$ t))
((eql f form) f)
(t (values f t)))))
nil)
(walker (form context env)
(cond
((symbolp form) (list form))
((atom form) form)
(t (if (find-$ form env)
(values `(setq $ ,form) t)
(values `(setq $ ,(list* (car form) '$ (cdr form))) t))))))
`(let (($ ,form))
,@(mapcar (lambda (f) (sb-walker:walk-form f nil #'walker)) body))))
How to understand this implementation? Well, clearly, we need to
understand what sb-walker:walk does. Broadly, it calls the walker
function (its third argument) on successive evaluated subforms of the
original form (and on variable names set by
setq);
the primary return value is used as the interim result of the walk,
subject to further walking (macroexpansion and walking of its
subforms) except if the second return value from the walker function
is t.
Now, let’s start with the find-$ local function: its job is to walk
a form, and returns t if it finds a $ variable to be evaluated at
toplevel and nil otherwise. It does that by returning t if the
form it’s given is $; otherwise, if the form it’s given is the
original form, we need to walk its subforms, so return f; otherwise,
return its form argument f with a secondary value of t to inhibit
further walking. This operation is slightly at odds with the use of a
code walker: we are explicitly not taking advantage of the fact that
it understands the semantics of the code it’s walking. This might
explain why the find-$ function itself looks a bit weird.
The walker local function is responsible for most of the code
transformation. It binds $ to the value of the first form, then
repeatedly sets $ to the value of successive forms, rewritten to
interpolate a $ in the first argument position if there isn’t one in
the form already (as reported by find-$). If any of the forms is a
symbol, it gets listified and subsequently re-walked. Thus
(macroexpand-1 '(-> "THREE" string-downcase (char 0)))
; => (LET (($ "THREE"))
; (SETQ $ (STRING-DOWNCASE $))
; (SETQ $ (CHAR $ 0))),
; T
So far, so good. Now, what could we do with a code-walker that we
can’t without? Well, the above implementation of -> supports
chaining simple function calls, so one answer is “chaining things that
aren’t just function calls”. Another refinement is to support eliding
the insertion of $ when there are any uses of $ in the form, not
just as a bare argument. Looking at the second one first, since it’s
less controversial:
(defmacro -> (form &body body)
(labels ((find-$ (form env)
(sb-walker:walk-form form env
(lambda (f c e)
(cond
((and (eql f '$) (eql c :eval))
(return-from find-$ t))
(t f))))
nil)
(walker (form context env)
(cond
((symbolp form) (list form))
((atom form) form)
(t (if (find-$ form env)
(values `(setq $ ,form) t)
(values `(setq $ ,(list* (car form) '$ (cdr form))) t))))))
`(let (($ ,form))
,@(mapcar (lambda (f) (sb-walker:walk-form f nil #'walker)) body))))
The only thing that’s changed here is the definition of find-$, and
in fact it’s a little simpler: the task is now to walk the entire form
and find uses of $ in an evaluated position, no matter how deep in
the evaluation. Because this is a code-walker, this will correctly
handle macros, backquotes, quoted symbols, and so on, and this allows
code of the form
(macroexpand-1 '(-> "THREE" string-downcase (char 0) char-code (complex (1+ $) (1- $))))
; => (LET (($ "THREE"))
; (SETQ $ (STRING-DOWNCASE $))
; (SETQ $ (CHAR-CODE $))
; (SETQ $ (COMPLEX (1+ $) (1- $)))),
; T
which, as far as I can tell, is not supported in magrittr: doing 3
%>% complex(.+1,.-1) is met with the error that “object '.' not
found”. Supporting this might, of course, not be a good idea, but at
least the code walker shows that it’s possible.
What if we wanted to augment -> to handle binding forms, or special
forms in general? This is probably beyond the call of duty, but let’s
just briefly imagine that we wanted to be able to support binding
special variables around the individual calls in the chain; for
example, we want
(-> 3 (let ((*random-state* (make-random-state))) rnorm) mean)
to expand to
(let (($ 3))
(setq $ (let ((*random-state* (make-random-state))) (rnorm $)))
(setq $ (mean $)))
and let us also say, to make it interesting, that uses of $ in the
bindings clauses of the let should not count against inhibiting
the insertion of $ in the first argument position of the first form
in the body of the let, so
(-> 3 (let ((y (1+ $))) (atan y)))
should expand to
(let (($ 3)) (setq $ (let ((y (1+ $))) (atan $ y))))
So our code walker needs to walk the bindings of the let, merely
collecting information into the walker’s lexical environment, then
walk the body performing the same rewrite as before. CHALLENGE
ACCEPTED:
(defmacro -> (&body forms)
(let ((rewrite t))
(declare (special rewrite))
(labels ((find-$ (form env)
(sb-walker:walk-form form env
(lambda (f c e)
(cond
((and (eql f '$) (eql c :eval))
(return-from find-$ t))
(t f))))
nil)
(walker (form context env)
(declare (ignore context))
(typecase form
(symbol (if rewrite (list form) form))
(atom form)
((cons (member with-rewriting without-rewriting))
(let ((rewrite (eql (car form) 'with-rewriting)))
(declare (special rewrite))
(values (sb-walker:walk-form (cadr form) env #'walker) t)))
((cons (member let let*))
(unless rewrite
(return-from walker form))
(let* ((body (member 'declare (cddr form)
:key (lambda (x) (when (consp x) (car x))) :test-not #'eql))
(declares (ldiff (cddr form) body))
(rewritten (sb-walker:walk-form
`(without-rewriting
(,(car form) ,(cadr form)
,@declares
(with-rewriting
,@body)))
env #'walker)))
(values rewritten t)))
(t
(unless rewrite
(return-from walker form))
(if (find-$ form env)
(values `(setq $ ,form) t)
(values `(setq $ ,(list* (car form) '$ (cdr form))) t))))))
`(let (($ ,(car forms)))
,@(mapcar (lambda (f) (sb-walker:walk-form f nil #'walker)) (cdr forms))))))
Here, find-$ is unchanged from the previous version; all the new
functionality is in walker. How does it work? The default branch
of the walker function is also unchanged; what has changed is
handling of
let
and
let*
forms. The main trick is to communicate information between
successive calls to the walker function, and turn the rewriting on and
off appropriately: we wrap parts of the form in new pseudo-special
operators with-rewriting and without-rewriting, which is basically
a tacky and restricted implementation of compiler-let – if we needed
to, we could do a proper one with
macrolet.
Within the scope of a without-rewriting, walker doesn’t do
anything special, but merely return the form it was given, except if
the form it’s given is a with-rewriting form. This is a nice
illustration, incidentally, of the idea that lexical scope in the code
translates nicely to dynamic scope in the compiler; I can’t remember
where I read that first (but it’s certainly not a new idea).
And now
(macroexpand '(-> 3 (let ((*random-state* (make-random-state))) rnorm) mean))
; => (LET (($ 3))
; (LET ((*RANDOM-STATE* (MAKE-RANDOM-STATE)))
; (SETQ $ (RNORM $)))
; (SETQ $ (MEAN $))),
; T
(macroexpand '(-> 3 (let ((y (1+ $))) (atan y))))
; => (LET (($ 3))
; (LET ((Y (1+ $)))
; (SETQ $ (ATAN $ Y)))),
; T
Just to be clear: this post isn’t advocating a smarter pipe operator;
I don’t have a clear enough view, but I doubt that the benefits of the
smartness outweigh the complexity. It is demonstrating what can be
done, in a reasonably controlled way, using a code-walker: ascribing
semantics to fragments of Common Lisp code, and combining those
fragments in a particular way, and of course it’s another example of
sb-walker:walk in use.
Finally, if something like this does in fact get used, people
sometimes get tripped up by the package system: the special bits of
syntax are symbols, and importing or package-qualifying -> without
doing the corresponding thing to $ would lead to cryptic errors,
wrong results and/or confusion. One possibility to handle that is to
invent a bit more reader syntax:
(set-macro-character #\¦
(defun pipe-reader (stream char)
(let ((*readtable* (copy-readtable)))
(set-macro-character #\·
(lambda (stream char)
(declare (ignore stream char))
'$) t)
(cons '-> (read-delimited-list char stream t)))) nil)
¦"THREE" string-downcase (find-if #'alpha-char-p ·) char-code¦
If this is the exported syntax, it has the advantage that the
interface can only be misused intentionally: the actual macro and its
anaphoric symbol are both hidden from the programmer; and the syntax
is reasonably easy to type – on my keyboard ¦ is AltGr+| and ·
is AltGr+. – and moderately mnemonic from shell pipes and function
notation respectively. It also has all the usual disadvantages of
reader-based interfaces, such as composability, somewhat mitigated if
pipe-reader is part of the macro’s exported interface.
I said in my
discussion about backquote representations
that some utilities had defects made manifest by
SBCL 1.2.2’s new internal
representation for backquote and related operators, and that those
defects could have been avoided by using a code-walker. I’m going to
look at let-over-lambda code here, to try to demonstrate what I
meant by that, and show how a proper code-walker can quite
straightforwardly be used for the code transformations that have been
implemented using a naïve walker (typically walking over a tree of
conses), removing whole classes of defects in the process.
The let-over-lambda code I’m discussing is from
https://github.com/thephoeron/let-over-lambda,
specifically
this version.
This isn’t intended to be a hatchet job on the utility – clearly, it
is of use to its users – but to show up potential problems and offer
solutions for how to fix them. I should also state up front that I
haven’t read the Let over Lambda book,
but it’s entirely possible that discussing and using a full
code-walker would have been out of scope (as it explicitly was for
On Lisp).
Firstly, let’s deal with how the maintainer of the let-over-lambda
code is dealing with the change in backquote representations, since
it’s still topical:
;; package definition here just in case someone decides to paste
;; things into a Lisp session, and for private namespacing
(defpackage "LOL" (:use "CL"))
(in-package "LOL")
;; actual excerpts from let-over-lambda code from
;; <https://github.com/thephoeron/let-over-lambda/blob/a202167629cb421cbc2139cfce1db22a84278f9f/let-over-lambda.lisp>
;; begins here:
#+sbcl
(if (string-lessp (lisp-implementation-version) "1.2.2")
(pushnew :safe-sbcl *features*)
(setq *features* (remove :safe-sbcl *features*)))
(defun flatten (x)
(labels ((rec (x acc)
(cond ((null x) acc)
#+(and sbcl (not safe-sbcl))
((typep x 'sb-impl::comma) (rec (sb-impl::comma-expr x) acc))
((atom x) (cons x acc))
(t (rec (car x) (rec (cdr x) acc))))))
(rec x nil)))
The issues around the
(*features*)
handling here have been reported at github; for
the purpose of this blog entry, I will just say that I wrote about
them in
Maintaining Portable Lisp Programs,
a long time ago, and that a better version might look a bit like this:
#+sbcl
(eval-when (:compile-toplevel :execute)
(defun comma-implementation ()
(typecase '`,x
(symbol 'old)
((cons symbol (cons structure-object)) 'new)))
(if (eql (comma-implementation) 'old)
(pushnew 'cons-walkable-backquote *features*)
(setq *features* (remove 'cons-walkable-backquote *features*))))
(defun flatten (x)
(labels ((rec (x acc)
(cond ((null x) acc)
#+lol::cons-walkable-backquote
((typep x 'sb-impl::comma) (rec (sb-impl::comma-expr x) acc))
((atom x) (cons x acc))
(t (rec (car x) (rec (cdr x) acc))))))
(rec x nil)))
With these changes, the code is (relatively) robustly testing for the
particular feature it needs to know about at the time that it needs to
know, and recording it in a way that doesn’t risk confusion or
contention with any other body of code. What is the let-over-lambda
library using flatten for?
(defun g!-symbol-p (thing)
(and (symbolp thing)
(eql (mismatch (symbol-name thing) "G!") 2)))
(defmacro defmacro/g! (name args &rest body)
(let ((syms (remove-duplicates
(remove-if-not #'g!-symbol-p (flatten body)))))
`(defmacro ,name ,args
(let ,(mapcar
(lambda (s)
`(,s (gensym ,(subseq (symbol-name s) 2))))
syms)
,@body))))
The intent behind this macro-defining macro, defmacro/g!, appears to
be automatic
gensym
generation: being able to write
(defmacro/g! with-foo ((foo) &body body)
`(let ((,g!foo (activate-foo ,foo)))
(unwind-protect
(progn ,@body)
(deactivate-foo ,g!foo))))
without any explicit calls to
gensym
but retaining the protection that gensyms give against name capture:
(macroexpand-1 '(with-foo (3) 4))
; => (let ((#1=#:FOO1 (activate-foo 3)))
; (unwind-protect
; (progn 4)
; (deactivate-foo #1#)))
That's fine; it’s reasonable to want something like this. Are there
any issues with this, apart from the one exposed by SBCL’s new
backquote implementation? In its conventional use, probably not –
essentially, all uses of g! symbols are unquoted (i.e. behind
commas) – but there are a couple of more theoretical points. One
issue is that flatten as it currently stands will look for all
symbols beginning with g! in the macroexpander function source,
whether or not they are actually variable evaluations:
(defmacro/g! with-bar ((bar) &body body)
`(block g!block
(let ((,g!bar ,bar)) ,@body)))
; unused variable G!BLOCK
(macroexpand-1 '(with-bar (3) 4))
; => (block g!block (let ((#:BAR1 3)) 4))
In this example, that’s fair enough: it’s probably user error to have
those g! symbols not be unquoted; this probably only becomes a real
problem if there are macro-defining macros, with both the definer and
the definition using g! symbols. It's not totally straightforward
to demonstrate other problems with this simple approach to Lisp code
transformation using just this macro; the transformation is
sufficiently minimal, and the symptoms of problems relatively
innocuous, that existing programming conventions are strong enough to
prevent anything seriously untoward going wrong.
Before getting on to another example where the problems with this
approach become more apparent, how could this transformation be done
properly? By “properly” here I mean that the defmacro/g! should
arrange to bind gensyms only for those g! symbols which are to be
evaluated by the macroexpander, and not for those which are used for
any other purpose. This is a task for a code-walker: a piece of code
which exploits the fact that Lisp code is made up of Lisp data
structures, all of which are introspectable, and the semantics of
which in terms of effect on environment and execution are known. It
is tedious, though possible, to write a mostly-portable code-walker
(there needs to be some hook into the implementation’s representation
of environments); I’m not going to do that here, but instead will use
SBCL’s built-in code-walker.
The sb-walker:walk-form function takes three arguments: a form to
walk, an initial environment to walk it in, and a walker function to
perform whatever action is necessary on the walk. That walker
function itself takes three arguments, a form, context and
environment, and the walker arranges for it to be called on every
macroexpanded or evaluated subform in the original form. The walker
function should return a replacement form for the subform it is given
(or the subform itself if it doesn’t want to take any action), and a
secondary value of
t if no
further walking of that form should take place.
To do g! symbol detection and binding is fairly straightforward. If
a symbol is in a context for evaluation, we collect it, and here we
can take the first benefit from a proper code walk: we only collect
g! symbols if the code-walker deems that they will be evaluated
and there isn't an already-existing lexical binding for it:
(defmacro defmacro/g!-walked (name args &body body)
(let* (g!symbols)
(flet ((g!-walker (subform context env)
(declare (ignore context))
(typecase subform
(symbol
(when (and (g!-symbol-p subform)
(not (sb-walker:var-lexical-p subform env)))
(pushnew subform g!symbols))
subform)
(t subform))))
(sb-walker:walk-form `(progn ,@body) nil #'g!-walker)
`(defmacro ,name ,args
(let ,(mapcar (lambda (s) (list s `(gensym ,(subseq (symbol-name s) 2))))
g!symbols)
,@body)))))
The fact that we only collect symbols which will be evaluated deals
with the problem exhibited by with-bar, above:
(defmacro/g!-walked with-bar/walked ((bar) &body body)
`(block g!block
(let ((,g!bar ,bar)) ,@body)))
(macroexpand-1 '(with-bar/walked (3) 4))
; => (block g!block (let ((#:BAR1 3)) 4))
Only gathering symbols which don’t have lexical bindings (testing
sb-walker:var-lexical-p) deals with another minor problem:
(defmacro/g!-walked with-baz ((baz) &body body)
(let ((g!sym 'sym))
`(let ((,g!sym ,baz)) ,@body)))
(macroexpand-1 '(with-baz (3) 4))
; => (let ((sym 3)) 4)
(the cons-walker – flatten – would not be able to detect that there
is already a binding for g!sym, and would introduce another one,
again leading to an unused variable warning.)
OK, time to recap. So far, we’ve corrected the code that tests for
particular backquote implementations, which was used in flatten,
which itself was used to perform a code-walk; we’ve also seen some
low-impact or theoretical problems with that simple code-walking
technique, and have used a proper code-walker instead of flatten to
deal with those problems. If the odd extra unused variable binding
were the worst thing that could happen, there wouldn’t be much benefit
from using a code-walker (other than the assurance that the walker is
dealing with forms for execution); however, let us now turn our
attention to the other macro in let-over-lambda’s code which does
significant codewalking:
(defun dollar-symbol-p (thing)
(and (symbolp thing)
(char= (char (symbol-name thing) 0) #\$)
(ignore-errors (parse-integer (subseq (symbol-name thing) 1)))))
(defun prune-if-match-bodies-from-sub-lexical-scope (tree)
(if (consp tree)
(if (or (eq (car tree) 'if-match)
(eq (car tree) 'when-match))
(cddr tree)
(cons (prune-if-match-bodies-from-sub-lexical-scope (car tree))
(prune-if-match-bodies-from-sub-lexical-scope (cdr tree))))
tree))
;; WARNING: Not %100 correct. Removes forms like (... if-match ...) from the
;; sub-lexical scope even though this isn't an invocation of the macro.
#+cl-ppcre
(defmacro! if-match ((test str) conseq &optional altern)
(let ((dollars (remove-duplicates
(remove-if-not #'dollar-symbol-p
(flatten (prune-if-match-bodies-from-sub-lexical-scope conseq))))))
(let ((top (or (car (sort (mapcar #'dollar-symbol-p dollars) #'>)) 0)))
`(let ((,g!str ,str))
(multiple-value-bind (,g!s ,g!e ,g!ms ,g!me) (,test ,g!str)
(declare (ignorable ,g!e ,g!me))
(if ,g!s
(if (< (length ,g!ms) ,top)
(error "ifmatch: too few matches")
;; lightly edited here to remove irrelevant use of #`
(let ,(mapcar (lambda (a1) `(,(symb "$" a1)
(subseq ,g!str (aref ,g!ms ,(1- a1))
(aref ,g!me ,(1- a1)))))
(loop for i from 1 to top collect i))
,conseq))
,altern))))))
(defmacro when-match ((test str) conseq &rest more-conseq)
`(if-match (,test ,str)
(progn ,conseq ,@more-conseq)))
What’s going on here? We have a
prune-if-match-bodies-from-sub-lexical-scope function which, again,
performs some kind of cons-based tree walk, removing some conses whose
car is if-match or when-match. We have a trivial macro
when-match which transforms into an if-match; the if-match macro
is more involved. Any symbols named as a $ sign followed by an
integer (in base 10) are treated specially; the intent is that they
will be bound to capture groups of the cl-ppcre match. So it would be
used in something like something like
(defun key-value (line)
(if-match ((lambda (s) (scan "^\\(.*\\): \\(.*\\)$" s)) line)
(list $1 $2)
(error "not actually a key-value line: ~S" line)))
and that would macroexpand to, roughly,
(defun key-value (line)
(multiple-value-bind (s e ms me)
((lambda (s) (scan "^\\(.*\\): \\(.*\\)$" s)) line)
(if s
(if (< (length ms) 2)
(error "if-match: not enough matches)
(let (($1 (subseq line (aref ms 0) (aref me 0)))
($2 (subseq line (aref ms 1) (aref me 1))))
(list $1 $2)))
(error "not actually a key-value line: ~S" line))))
(there's additional reader macrology in let-over-lambda to make that
lambda form unnecessary, but we can ignore that for our purposes).
Now, if-match has a similar problem that defmacro/g! had: since
the tree walker doesn’t make a distinction between symbols present for
evaluation and symbols for any other purpose, it is possible to
confuse the walker. For example:
(if-match (scanner string)
(if (> (length $1) 6)
'|$1000000|
'less-than-$1000000))
This form, if macroexpanded, will attempt to bind one million variables to matched groups; even if the compiler doesn’t choke on that, evaluation will go wrong, as the matcher is unlikely to match one million groups (so the “not enough matches” error branch will be taken) – whereas of course the quoted one million dollar symbol is not intended for evaluation.
But the nesting problems are more obvious in this case than for
defmacro/g!. Firstly, take the simple case:
(if-match (scanner string)
(list $1
(if-match (scanner2 string)
$2
nil))
nil)
Here, the $2 is in the scope of the inner if-match, and so mustn’t
be included for the macroexpansion of the outer if-match. This case
is handled in let-over-lambda’s implementation by the
prune-if-match-bodies-from-sub-lexical-scope: the consequent of the
inner if-match is pruned from the dollar-symbol accumulator.
However, there are several issues with this; the first is that the
test is pruned:
(if-match (scanner string)
(if-match (scanner2 $2)
$1
nil)
nil)
In this example, the $2 is ‘invisible’ to the outer if-match, and
so won’t get a binding. That’s straightforwardly fixable, along with
the mishandling of when-let’s syntax (the entire body of when-let
should be pruned, not just the first form), and what I think is an
error in the pruning of if-match (it should recurse on the cdddr,
not the cddr;
github issue).
Not fixable at all while still using naïve code-walking are two other
problems, one of which is noted in the comment present in the
let-over-lambda code: the pruner doesn’t distinguish between
if-match forms for evaluation and other conses whose car is
if-match. Triggering this problem does involve some contortions –
in order for it to matter, we need an if-match not for evaluation
followed by a dollar symbol which is to be evaluated; but, for
example:
(defmacro list$/q (&rest args)
`(list ,@(mapcar (lambda (x) (if (dollar-symbol-p x) x `',x)) args)))
(if-match (scanner string)
(list$/q foo if-match $2)
nil)
Here, although the $2 is in a position for evaluation (after
macroexpansion), it will have no binding because it will have been
pruned when naïvely walking the outer if-match macro. The
if-match symbol argument to `list$/q ends up quoted, and should not
be treated as a macro call.
Also, the pruner function must have special knowledge not just about
the semantics of if-match, but also of any macro which can expand
to if-match – see the attempt to handle when-match in the pruner.
If a user were to have the temerity to define case-match
(defmacro case-match (string &rest clauses)
(if (null clauses)
nil
`(if-match (,(caar clauses) ,string)
(progn ,@(cdar clauses))
(case-match string ,@(cdr clauses)))))
any attempt to nest a case-match inside an outer if-match is
liable to fail, as the pruner has no knowledge of how to handle the
case-match form.
All of these problems are solvable by using a proper code-walker. The
code-walker should collect up all dollar symbols to be evaluated in
the consequent of an if-match form, so that bindings for them can be
generated, except for those with already existing lexical bindings
within the if-match (not those from outside, otherwise nesting
won’t work). For testing purposes, we’ll also signal a diagnostic
condition within the macroexpander to indicate which dollar symbols
we’ve found.
(define-condition if-match/walked-diagnostic (condition)
((symbols :initarg :symbols :reader if-match-symbols)))
(defmacro if-match/walked ((test string) consequent &optional alternative)
(let* (dollar-symbols)
(flet ((dollar-walker (subform context env)
(declare (ignore context))
(typecase subform
(symbol
(when (and (dollar-symbol-p subform)
(not (sb-walker:var-lexical-p subform env)))
(pushnew subform dollar-symbols))
subform)
(t subform))))
(handler-bind ((if-match/walked-diagnostic #'continue))
(sb-walker:walk-form consequent nil #'dollar-walker))
(let* ((dollar-symbols (sort dollar-symbols #'> :key #'dollar-symbol-p))
(top (dollar-symbol-p (car dollar-symbols))))
(with-simple-restart (continue "Ignore diagnostic condition")
(signal 'if-match/walked-diagnostic :symbols dollar-symbols))
(sb-int:with-unique-names (start end match-start match-end)
(sb-int:once-only ((string string))
`(multiple-value-bind (,start ,end ,match-start ,match-end)
(,test ,string)
(declare (ignore ,end) (ignorable ,match-end))
(if ,start
(if (< (length ,match-start) ,top)
(error "~S: too few matches: needed ~D, got ~D." 'if-match
,top (length ,match-start))
(let ,(mapcar (lambda (s)
(let ((i (1- (dollar-symbol-p s))))
`(,s (subseq ,string (aref ,match-start ,i) (aref ,match-end ,i)))))
(reverse dollar-symbols))
,consequent))
,alternative))))))))
(I'm using sb-int:once-only and sb-int:with-unique-names to avoid
having to include their definitions in this post, which is getting a
bit lengthy). Testing this looks like
(defmacro test-if-match (form expected-symbols)
`(handler-case (macroexpand-1 ',form)
(if-match/walked-diagnostic (c)
(assert (equal (if-match-symbols c) ',expected-symbols)))
(:no-error (&rest values) (declare (ignore values)) (error "no diagnostic"))))
(test-if-match (if-match/walked (test string) (list $1 $2) 'foo) ($2 $1))
(test-if-match (if-match/walked (test string) (if (> (length $1) 6) '$10 '$8) nil) ($1))
(test-if-match (if-match/walked (scanner string)
(list $1
(if-match/walked (scanner2 string)
$2
nil))
nil)
($1))
(test-if-match (if-match/walked (scanner string) (list$/q foo if-match/walked $3) nil) ($3))
(defmacro case-match/walked (string &rest clauses)
(if (null clauses)
nil
`(if-match/walked (,(caar clauses) ,string)
(progn ,@(cdar clauses))
(case-match/walked string ,@(cdr clauses)))))
(test-if-match (if-match/walked (scanner string)
(case-match/walked $1
(foo $2)
(bar $3)))
($1))
To summarize: I’ve shown here how to make use of a full code-walker to
make a couple of code transforming macros more robust. Full
code-walkers can do more than just what I've shown here: the
sb-walker:walk-form interface can also inhibit macroexpansion,
transform function calls into calls to other functions, while
respecting the semantics of the Lisp operators in the code that is
being walked and allowing some introspection of the lexical
environment. Here, we have called sb-walker:walk-form for side
effects from the walker function we’ve provided; it is also possible
to use its value (that’s how sb-cltl2:macroexpand-all is
implemented, for example). I hope that this can help users affected
by the change in internal representation of backquote, as well as
others who want to write advanced code-transforming macros. If the
thought of using an SBCL-internal code-walker makes you a bit queasy
(as well it might), you could instead start by looking at one or two
other more explicitly-portable code-walkers out there, for example
John Fremlin’s
macroexpand-dammit, the
walker in Alex Plotnick's
CLWEB literate
programming system
(github link), or the code
walker in iterate.
There was a bit of a kerfuffle following the 1.2.2 release of SBCL, regarding the incompatible change in the internals of the backquote reader macro.
Formally, implementations can choose how to implement the backquote reader macro (and its comma-based helpers): the semantics of backquote are defined only after evaluation:
An implementation is free to interpret a backquoted form F1 as any form F2 that, when evaluated, will produce a result that is the same under equal as the result implied by the above definition, provided that the side-effect behavior of the substitute form F2 is also consistent with the description given above.
(CLHS 2.4.6; emphasis mine)
There are also two advisory notes about the representation:
Often an implementation will choose a representation that facilitates pretty printing of the expression, so that
(pprint '`(a ,b))will display`(a ,b)and not, for example,(list 'a b). However, this is not a requirement.
(CLHS 2.4.6.1; added quote in example mine), and:
Implementors who have no particular reason to make one choice or another might wish to refer to IEEE Standard for the Scheme Programming Language, which identifies a popular choice of representation for such expressions that might provide useful to be useful compatibility for some user communities.
(CLHS 2.4.6.1;
the Scheme representation reads `(foo ,bar) as (quasiquote (foo
(unquote bar))))
The problem the new implementation of backquote is attempting to
address is the first one: pretty printing. To understand what the
problem is, an example might help: imagine that we as Common Lisp
programmers (i.e. not implementors, and aiming for portability) have
written a macro bind which is exactly equivalent to let:
(defmacro bind (bindings &body body)
`(let ,bindings ,@body))
and we want to implement a pretty printer for it, so that (pprint
'(progn (bind ((x 2) (z 3)) (if *print-pretty* (1+ x) (1- y)))))
produces
(progn
(bind ((x 2)
(z 3))
(if *print-pretty*
(1+ x)
(1- y))))
What does that look like? Writing pretty-printers is a little bit of a black art; a first stab is something like:
(defun pprint-bind (stream object)
(pprint-logical-block (stream object :prefix "(" :suffix ")")
(pprint-exit-if-list-exhausted)
(write (pprint-pop) :stream stream)
(pprint-exit-if-list-exhausted)
(write-char #\Space stream)
(pprint-logical-block (stream (pprint-pop) :prefix "(" :suffix ")")
(pprint-exit-if-list-exhausted)
(loop
(write (pprint-pop) :stream stream)
(pprint-exit-if-list-exhausted)
(pprint-newline :mandatory stream)))
(pprint-exit-if-list-exhausted)
(pprint-indent :block 1 stream)
(pprint-newline :mandatory stream)
(loop
(write (pprint-pop) :stream stream)
(pprint-exit-if-list-exhausted)
(pprint-newline :mandatory stream))))
(set-pprint-dispatch '(cons (eql bind)) 'pprint-bind)
The
loop
noise is necessary because we're using :mandatory newlines; a
different newline style, such as :linear, might have let us use a
standard utility function such as
pprint-linear.
But otherwise, this is straightforward pretty-printing code, doing
roughly the equivalent of SBCL's internal pprint-let implementation,
which is:
(formatter "~:<~^~W~^ ~@_~:<~@{~:<~^~W~@{ ~_~W~}~:>~^ ~_~}~:>~1I~:@_~@{~W~^ ~_~}~:>")
A few tests at the repl should show that this works with nasty,
malformed inputs (“malformed” in the sense of not respecting the
semantics of bind) as well as expected ones:
(pprint '(bind))
(pprint '(bind x))
(pprint '(bind x y))
(pprint '(bind (x y) z))
(pprint '(bind ((x 1) (y 2)) z))
(pprint '(bind ((x 1) (y 2)) z w))
(pprint '(bind . 3))
(pprint '(bind x . 4))
(pprint '(bind (x . y) z))
(pprint '(bind ((x . 0) (y . 1)) z))
(pprint '(bind ((x) (y)) . z))
(pprint '(bind ((x) y) z . w))
Meanwhile, imagine a world where the backquote reader macro simply
wraps (quasiquote ...) around its argument, and comma likewise wraps
(unquote ...):
(set-macro-character #\` (defun read-backquote (stream char)
(list 'quasiquote (read stream t nil t))))
(set-macro-character #\, (defun read-comma (stream char)
(list 'unquote (read stream t nil t))))
Writing pretty-printer support for that is easy, right?
(defun pprint-quasiquote (stream object)
(write-char #\` stream)
(write (cadr object) :stream stream))
(defun pprint-unquote (stream object)
(write-char #\, stream)
(write (cadr object) :stream stream))
(set-pprint-dispatch '(cons (eql quasiquote) (cons t null)) 'pprint-quasiquote)
(set-pprint-dispatch '(cons (eql unquote) (cons t null)) 'pprint-unquote)
(ignoring for the moment what happens if the printed representation of
object happens to start with a @ or .)
(pprint '(quasiquote (x (unquote y))))
The problem arises when we try to combine these two things. In particular, what happens when we attempt to print backquoted forms:
(pprint '`(bind ,y z))
What we would hope to see is something like
`(bind ,y
z)
but what we actually get is
`(bind (unquote
y)
z)
because each of the bindings in bind is printed individually, rather
than the bindings being printed as a whole. And, lest there be hopes
that this can be dealt with by a slightly different way of handling
the pretty printing in pprint-bind, note that it's important that
(pprint '(bind (function y) z)) print as
(bind (function
y)
z)
and not as
(bind #'y
z)
so the only way to handle this is to know the magical symbols involved
in backquote and comma reader macros – but that is not portably
possible. So, we've come to the point where the conclusion is
inevitable: it is not possible for an implementation to support
list-structured quasiquote and unquote reader macros and general
pretty printing for user-defined operators. (This isn’t the only
failure mode for the combination of unquote-as-list-structure and
pretty-printing; it’s surprisingly easy to write pretty-printing
functions that fail to print accurately, not just cosmetically as
above but catastrophically, producing output that cannot be read back
in, or reads as a structurally unequal object to the original.)
The new implementation, by Douglas Katzman, preserves the
implementation of the backquote reader macro as a simple list, but
comma (and related reader macros) read as internal, literal
structures. Since these internal structures are atoms, not lists,
they are handled specially by
pprint-logical-block
and friends, and so their own particular pretty-printing routines
always fire. The internal quasiquote macro ends up extracting and
arranging for appropriate evaluation and splicing of unquoted
material, and everything ends up working.
Everything? Well, not quite: one or two programmer libraries out
there implemented some utility functionality – typically variable
renaming, automatic lambda generation, or similar – without performing
a full macroexpansion and proper codewalk. That code was in general
already broken, but it is true that in the past generating an example
to demonstrate the breakage would have to violate the general
expectation of what “normal” Lisp code would look like, whereas as a
result of the new implementation of backquote in SBCL the symptoms of
breakage were much easier to generate. Several of these places were
fixed before the new implementation was activated, such as
iterate's #l macro; among
the things to be dealt with after the new implementation was released
was the utility code from let-over-lambda
(a workaround has been installed in the
version distributed from github),
and there is still a little bit of fallout being dealt with (e.g. a
regression in the accuracy of source-location tracking).
But overall, I think the new implementation of backquote has
substantial advantages in maintainability and correctness, and while
it’s always possible to convince maintainers that they’ve made a
mistake, I hope this post explains some of why the change was made.
Meanwhile, I've released SBCL version 1.2.3 – hopefully a much less “exciting” release...
There’s seems to be something about rainy weekends in May that stimulates academics in Computing departments to have e-mail discussions about programming languages and teaching. The key ingredients probably include houseboundness, the lull between the end of formal teaching and the start of exams, the beginning of contemplation of next year’s workload, and enthusiasm; of course, the academic administrative timescale is such that any changes that we contemplate now, in May 2014, can only be put in place for the intake in September 2015... if you’ve ever wondered why University programmes in fashionable subjects seem to lag about two years behind the fashion (e.g. the high growth of Masters programmes in “Financial Engineering” or similar around 2007 – I suspect that demand for paying surprisingly high tuition fees for a degree in Synthetic Derivative Construction weakened shortly after those programmes came on stream, but I don’t actually have the data to be certain).
Meanwhile, I was at the European Lisp Symposium in Paris last week, where there was a presentation of a very apposite nature: the Computing Department at Middlesex university has implemented an integrated first-year of undergraduate teaching, covering a broad range of the computing curriculum (possibly not as broad as at Goldsmiths, though) through an Arduino and Raspberry Pi robot with a Racket-based programmer interface. Students’ progress is evaluated not through formal tests, courseworks or exams, but through around 100 binary judgments in the natural context of “student observable behaviours” at three levels (‘threshold’, which students must exhibit to progress to the second year; ‘typical’, and ‘excellent’).
This approach has a number of advantages, I think, over a more traditional division of the year into four thirty-credit modules (e.g. Maths, Java, Systems, and Profession): for one, it pretty much guarantees a coherent approach to the year, where in the divided modules case it is surprisingly easy for one module to be updated in syllabus or course content without adjustments to the others, leaving for example some programming material insufficiently supported by the maths (and some maths taught without motivation). The assessment method is in principle transparent to the students, who know what they have to do to progress (and to get better marks); I'm not convinced that this is always a good thing, but for an introductory and core course I think the benefits substantially outweigh the disadvantages. The use of Racket as the teaching language has an equalising effect – it’s unlikely that students will have prior experience with it, so everyone starts off at the same point at least with respect to the language – and the use of a robot provides visceral feedback and a sense of achievement when it is made to do something in a way that text and even pixels on a screen might not. (This feedback and tangible sense of achievement is perhaps why the third-year option of Physical Computing at Goldsmiths is so popular: often oversubscribed by a huge margin).
With these thoughts bubbling around in my head, then, when the annual discussion kicked off at the weekend I decided to try to articulate my thoughts in a less ephemeral way than in the middle of a hydra-like discussion: so I wrote a wiki page, and circulated that. One of the points of having a personal wiki is that the content on it can evolve, but before I eradicate the evidence of what was there before, and since it got at least one response (beyond “why don’t you allow comments on your wiki?”) it's worth trying to continue the dialogue.
Firstly, Chris Cannam pulls me up on not including an Understand goal, or one like it: teaching students to understand and act on their understanding of computing artifacts, hardware and software. I could make the argument that this lives at the intersection of my Think and Experiment goals, but I think that would be retrospective justification and that there is a distinct aim there. I’m not sure why I left it out; possibly, I am slightly hamstrung in this discussion about pedagogy by a total absence of formal computing education; one course in fundamentals of computing as a 17-year-old, and one short course on Fortran and numerical methods as an undergraduate, and that’s it. It's in some ways ironic that I left out Understand, given that in my use of computers as a hobby it’s largely what I do: Lisp software maintenance is often a cross between debugger-oriented programming and software archaeology. But maybe that irony is not as strong as it might seem; I learnt software and computing as a craft, apprenticed to a master; I learnt the shibboleths (“OAOO! OAOO! OAOO!”) and read the training manuals, but I learnt by doing, and I’m sure I’m far from alone, even in academic Computing let alone among programmers or computing professionals more generally.
Maybe the Middlesex approach gets closer, in the University setting, to the apprenticeship (or pre-apprenticeship) period; certainly, there are clear echoes in their approach of the switch by MIT from the SICP- and Scheme-based 6.001 to the Robotics- and Python-based introduction to programming – and Sussman’s argument from the time of the switch points to a qualitative difference in the role of programmers, which happens to dovetail with current research on active learning. In my conversation with the lecturers involved after their presentation, they said that the students take a more usual set of languages in their second-years (Java, C++); obviously, since this is the first year of their approach, they don’t yet know how the transition will go.
And then there was the slightly cynical Job vs Career distinction that I drew, being the difference between a graduate-level job six months after graduation as distinct from a fulfilling career. One can of course lead to the other, but it’s by no means guaranteed, and I would guess that if asked most people would idealistically say we as teachers in Universities should be attempting to optimize for the latter. Unfortunately, we are measured in our performance in the former; one of the “Key Information Sets” collected by higher-education agencies and presented to prospective undergraduates is the set of student ‘destinations’. Aiming to optimize this statistic is somewhat akin to schools optimizing their GCSE results with respect to the proportion of pupils gaining at least 5 passes: ideally, the measurement should be a reflection of the pedagogical practice, but the foreknowledge of the measurement has the potential to distort the allocation of effort and resources. In the case of the school statistic, there’s evidence that extra effort is concentrated on borderline pupils, at the expense of both the less able and potential high-fliers; the distortion isn’t so stark in the case of programming languages, because the students have significant agency between teaching and measurement, but there is certainly pressure to ensure that we teach the most common language used in assessment centres.
In Chris’ case, C++ might have had a positive effect on both; the programming language snob in me, though, wants to believe that there are hordes of dissatisfied programmers out there, having got a job using their competence in some “industry-standard” language, desperately wanting to know about a better way of doing things. I might be overprojecting the relationship of a professional programmer with their tools, of course: for many a career in programming and development is just that, rather than a love-hate relationship with their compiler and linker. (Also, there’s the danger of showing the students that there is a better way, but that the market doesn’t let them use it...)
Is it possible to conclude anything from all of this? Well, as I said in my initial thoughts, this is an underspecified problem; I think that a sensible decision can only be taken in practice once the priorities for teaching programming at all have been established, in combination with the resources available for delivering teaching. I’m also not enough of a polyglot in practice to offer a mature judgment on many fashionable languages; I know enough of plenty of languages to modify and maintain code, but am comfortable writing from scratch in far fewer.
So with all those caveats, an ideal programming curriculum (reflecting my personal preferences and priorities) might include in its first two years: something in the Lisp family, for Think and Experiment; ARM Assembler, for Think and Understand; C++, for Job and Career (and all three together for Society). Study should probably be handled in individual third-year electives, and I would probably also include a course hybrid between programming, database and system administration to cover a Web programming stack for more Job purposes. Flame on (but not here, because system administration is hard).
My train ride to Paris was uneventful, and I
arrived at my accommodation only several hours after bedtime. I did
manage to write my talk, and it was good to discover the number of
obsessive planet.lisp readers when I
showed up to register – “good to see you again. How’s the talk?” was
the median greeting. For the record, I had not only written my talk
on the train but also had a chance to relax a little. Go trains.
The conference was fun; gatherings of like-minded people usually are, but of course it takes substantial effort from determined people to create the conditions for that to happen. Kent’s work as programme chair, both before and during the conference, came with a feeling of apparent serenity while never for a moment looking out of control, and the groundwork that the local organizing team (Didier Verna, Gérard Assayag and Sylvie Benoit) had done meant that even the problem of the registrations exceeding the maximum capacity of the room – nice problem to have! – could be dealt with.
I liked the variety in the keynotes. It was very interesting to hear Richard Gabriel’s talk on his research in mood in Natural Language processing and generation; in many ways, those research directions are similar to those in the Transforming Musicology world. The distinction he drew between programming for a purpose and programming for exploration was very clear, too: he made it clear that he considered them two completely different things, and with my hat as a researcher on I have to agree: usually when I'm programming for research I don’t know what I'm doing, and the domain of investigation is so obviously more unknown than the program structure that I had better have a malleable environment, so that I can minimize the cost of going down the wrong path. Pascal Costanza gave a clear and detailed view of the problems in parallel programming, drawing a distinction between parallelism and concurrency, and happened to use examples from several of my previous lives (Smooth-Particle Hydrodynamics, Sequence Alignment) to illustrate his points. Gábor Melis talked about his own learning and practice in the context of machine learning, with a particular focus on his enviable competition record; his call to aim for the right-hand side of the curves (representing clear understanding and maximum use-case coverage) was accompanied by announcements of two libraries, mgl-pax and mgl-mat.
My own presentation was, I suppose, competent enough
(slides). Afterwards, I had a good talk with my
previous co-author in the generalizes research line, Jim Newton, about
the details, and Gábor told me he’d like to try it “on by default”.
But the perils of trying to get across a highly-technical topic
struck, and I got a number of comments of the form that the talk had
been enjoyable but I’d “lost them at
compute-applicable-methods-using-classes”.
I suppose I could still win if the talk was enjoyable enough for
them to read and work through the paper; maybe next time I might risk
the demo effect rather more than I did and actually do some
programming live on stage, to help ground the ideas in people’s minds.
I did get a specific request: to write a blog post about
eval-when
in the context of metaobject programming, and hopefully I'll find time
for the in the next few train journeys...
Meanwhile, highlights (for me) among the contributed papers:
Nick Levine driving Lispworks’
CAPI graphical user interface library from SBCL using his
Common Lisp AUdience Expansion
toolkit (preaching to the choir, though: his real target is Python
developers); Faré Rideau’s description
of a
decade-long exploration of defsystem design space;
François-Xavier Bois’ demonstration of
web-mode.el, an Emacs mode capable of
handling CSS, Javascript and PHP simultaneously; and two talks
motivated by pedagogy: Pedro Ramos’ discussion of the design tradeoffs
involved in an implementation of Python in Racket, and the team
presentation of the approach taken for a new robotics- and
Scheme-oriented undergraduate first-year at Middlesex University, on
which more in a subsequent post.
Lightning talks of particular note to me: Martin Simmons talking about Lispworks for mobile; Didier Verna and Marco Antoniotti talking about their respective documentation generation systems (my response); Mikhail Raskin’s argument about the opportunity to push Julia in a lispy direction; and probably others which will come back to mind later.
I was also pleased to be able to contribute to the last full session of the symposium, a workshop/panel about Lisp in the area of music applications: an area which is serendipitously close to the day job. I worked on getting a version of audioDB, our feature-vector search engine for similarity matching, built and working on my laptop, and finding a sufficiently interesting search among my Gombert/Josquin collection to demo – and I also had the chance to talk about Raymond Whorley’s work on using multiple viewpoint systems for hymn harmonizations, and what that teaches us about how people do it (slides, for what they're worth). Other systems of interest in the session included OpenMusic (of course, given where we were), PWGL, OMax, modalys, and overtone; there was an interesting conversation about whether the choice of implementation language was restricting the userbase, particularly for tools such as OpenMusic where the normal interface is a graphical one but a large fraction of users end up wanting to customize behaviour or implement their own custom patches.
And then it was all over bar the dinner! On a boat, sadly immobile, but with good conversation and good company. The walk home in company was fun, though in retrospect it was probably a mistake to stop off at a bar for a nightcap... the train journey back to the UK the following morning was definitely less productive than it could have been; closing eyes and letting the world go past was much more attractive.
But now I'm on another train, going off to record the complete works of Bernadino de Ribera. Productivity yay.
After a packed weekend of music-making with De Profundis (go buy tickets!), I’m now at St Pancras, waiting for a train to Paris to go to the European Lisp Symposium, where I’ll be presenting my work (with Jan Moringen and David Lichteblau) on generalizer metaobjects. I’m looking forward to the event: it’s being held at IRCAM, which as an institution neatly combines two of my interests (computing and music) – there’s going to be a special session on Tuesday on Lisp and composition, though I might try to participate and broaden it a bit to talk about some of our current problems and approaches in Transforming Musicology.
I’m not (yet) looking forward to my talk. Over the next few hours, I’m going to be putting to the test my current belief that I am most productive on trains, because I haven’t yet written my talk, and it turns out that I am in the first session tomorow morning. (I know, I know, this is the sound of the world’s tiniest violin). 2h20 should be enough fo anyone.
The flip side of the stress of being first is the ability to enjoy the
rest of the symposium without the stress of an upcoming presentation
hanging over me – as well as the ability to ask nasty difficult
and probing questions without too much fear of instant reprisal. (I
suppose that by putting this out there before the talk I open myself
up to pre-reprisals; all I can say is that I welcome a constructive
and robust exchange of views: there is definitely more work to be done
in the world of extended dispatch, and suggestions will be welcome.)
And of course it will be good to meet up with a community of
like-minded people; I may not be highly active in the Lisp world these
days (though I have been making an effort to be more engaged with at
least the SBCL team for more than the one day
a month of release activity, and it’s been fun to watch the
ARM port progress on #sbcl) but I retain a
good helping of interest in what’s going on, and it will be great to
meet up with old friends and maybe even to make new ones.
(Registration got to the room capacity very quickly, and hopefully
the overflow room will have a good atmosphere too). Hopefully the
conversations I have and ideas generated will mean that I have a
productive train ride back, too!
Sometimes, it feels like old times, rolling back the years, and so on. One of the things I did while avoiding work on my PhD (on observational tests of exotic cosmologies inspired by then-fashionable high-energy physics theories, since you ask) was to assist in resurrecting old and new CMUCL backends for SBCL, and to do some additional backend hacking. I learnt a lot! (To be fair, I learnt a lot about General Relativity too). And I even wrote about some of the funny bits when porting, such as getting to a working REPL with a completely broken integer multiply on SPARC, or highly broken bignums when working on a proper 64-bit backend for alpha.
On the #sbcl IRC channel over the last few days, the ARM porting
crew (not me! I've just been kibitzing) has made substantial
progress, to the point that it's now possible to boot a mostly-working
REPL. Some of the highlights of the non-workingness:
(truncate (expt 2 32) 10)
21074691228794313799883120286105
6
(fib 50)
6277101738309684039858724727853387073209631205623600462197
(expt 2.0 3)
2.0
(sb-ext:run-program "uname" '() :search t :output *standard-output*)
Linux
Memory fault at 3c
Meanwhile, given that most ARM cores don't have an integer division instruction, it's a nice bit of synchronicity that one of this year's Summer of Code projects for SBCL is to improve division by constant integers; I'm very much looking forward to getting involved with that, and hopefully also bringing some of the next generation of SBCL hackers into the community. Maybe my writing a while back about a self-sustaining system wasn't totally specious.
I promised a non-trivial example of a use for generalized specializers a while ago. Here it is: automatic handling of HTTP (RFC 2616) Content-Type negotiation in computed responses.
In RESTful services and things of that ilk, a client indicates that it wants to apply a verb (GET, for example) to a particular resource (named by a URN, or possibly identified by a URI). This resource is a conceptual object; it will have zero or more concrete manifestations, and content negotiation provides a way for the client to indicate which of those manifestations it would prefer to receive.
That's all a bit abstract. To take a concrete example, consider the woefully incomplete list of books in my living room at openlibrary. A user operating a graphical web browser to access that resource is presumed to want to retrieve HTML and associated resources, in order to view a shiny representation of the information associated with that resource (a “web page”, if you will). But the human-oriented representation of the information is not the only possible one, and it is common practice in some circles to provide machine-readable representations as well as human-oriented ones, at the same URL; for example, try:
curl -H 'Accept: application/json' https://openlibrary.org/people/csrhodes/lists
and observe the difference between that and visiting the same URL in a graphical browser.
How does the web server know which representation to send? Well, the
example has given away the punchline (if the links above to RFC
sections haven't already). The graphical web browser will send an
Accept header indicating that it prefers to receive objects with
presentational content types – text/html, image/* and so on; the
browser I have to hand sends
text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 as
its Accept header, meaning “please give me text/html or
application/xhtml+xml, or failing that application/xml, or failing
that anything else”. If the server has more than one representation
for a given resource, it can use this client-supplied information to
provide the best possible content; if the client has particular
requirements – for example, attempting to find machine-readable
content for further processing – it can declare this by specifying
particular acceptable content-types in its Accept header.
For a resource for which more than one representation exists, then,
the server must dispatch between them based on the client Accept
header. And this is exactly a non-standard dispatch of the kind I've
been discussing. Consider a resource http://foo.example/ which is
implemented by sending the return value of the generic function foo
back to the client:
(defgeneric foo (request)
(:generic-function-class accept-generic-function))
The default behaviour is somewhat a matter of taste, but one reasonable choice is that if no content-type matches we should use the defined HTTP status code to indicate that the responses we could generate are not acceptable to the client:
(defmethod foo ((request t))
(http:406 request))
Maybe we have a couple of presentational representations for the resource:
(defmethod foo ((request (accept "text/plain")))
"Foo")
(defmethod foo ((request (accept "text/html")))
"<!DOCTYPE html>
<html>
<head><title>Foo</title></head>
<body><p>Foo</p></body>
</html>")
And we might have some machine-readable representations:
(defmethod foo ((request (accept "text/turtle")))
"@prefix foo: <http://example.org/ns#> .
@prefix : <http://other.example.org/ns#> .
foo:bar foo: : .")
(defmethod foo ((request (accept "application/rdf+xml")))
"<?xml version=\"1.0\"?>
<rdf:RDF xmlns:rdf=\"http://www.w3.org/1999/02/22-rdf-syntax-ns#\"
xmlns:foo=\"http://example.org/ns#\">
<rdf:Description about=\"http://example.org/ns#bar\">
<foo:>
<rdf:Description about=\"http://other.example.org/ns#\"/>
</foo:>
</rdf:Description>
</rdf:RDF>")
(I apologize to any fans of XML/RDF if I have mangled that).
Now a graphical web browser sending an accept header of
text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 as
above will cause the server to send the HTML version, as that is the
most specific applicable method to that accept string. Given this,
it is perfectly possible to construct specialized clients with
alternative preferences expressed in the accept header. A
terminal-based client might prioritize text/plain over text/html
(though in fact neither w3m nor
lynx does that, at least in the versions I
have installed). A client for the Semantic Web might instead accept
data in serialized RDF, preferring more modern serializations, by
sending an accept string of text/turtle,application/rdf+xml;q=0.9.
All these clients could each be served the resource in their preferred
format.
The case of serving one of a set of alternative files hosted on the filesystem in response to a request with an arbitrary accept string is different; in this case, it doesn't make sense to do the dispatch through methods. If we were to try to do so, it would look something like
(defmethod filesystem-handler (url (content-type (accept "text/html")))
(let ((prospect (pathname-for-url url "html")))
(if (probe-file prospect)
(serve-file prospect "text/html")
(call-next-method))))
but we would need to define one such method per possible mime-type we might want to serve: doable, but unnecessary compared with the alternative strategy of finding all content-types servable for a given url, then choosing the one with the highest score:
(defun filesystem-handler (url accept)
(do* ((prospects (files-for url) (cdr prospects))
(mime-types (mapcar #'mime-type prospects) (cdr mime-types))
result mime-type (q 0))
((null prospects) (serve-file result mime-type))
(when (> (q (car mime-types) accept) q)
(setf result (car prospects)
mime-type (car mime-types)
q (q (car mime-types))))))
(the set of files on the filesystem effectively already define a set
of methods for a given url; it doesn't make sense to try to mirror
that as a set of reified methods on a generic function. Also, I've
written this out using
do*
largely to keep the do*-is-not-that-bad society alive.)
Anyway. There's an interesting detail I've elided so far; not only do
response-generating functions have to generate the content they wish
to send in the response; they also have to indicate what
content-type they are actually sending. Our accept-generic-function
already handles dispatching on content-type; can it also take
responsibility for setting the content-type of the response?
Why yes! The way to do this is using a method combination; it might look something like this:
(defvar *actual-content-type*)
(defgeneric handle-content-type (request))
(define-method-combination content-negotiation/or ()
((around (:around))
(primary () :required t))
(:arguments request)
(labels ((transform/1 (method)
`(make-method
(progn
(let ((s (car (sb-mop:method-specializers ,method))))
(when (typep s 'accept-specializer)
(setf *actual-content-type* (media-type s))))
(call-method ,method))))
(transform (primaries)
(mapcar #'(lambda (x) `(call-method ,(transform/1 x)))
primaries))
(wrap (form)
`(let ((*actual-content-type*))
(multiple-value-prog1
,form
(handle-content-type ,request)))))
(let ((form (if (rest primary)
`(or ,@(transform primary))
`(call-method ,(transform/1 (car primary))))))
(if around
(wrap `(call-method ,(first around)
(,@(rest around) (make-method ,form))))
(wrap form)))))
This behaves just like the or built-in
method-combination,
except that when calling a primary method whose specializer for the
first argument is one of our accept-specializers, the content-type
of the specializer is stored in a special variable; the last thing the
effective method does is to call the new handle-content-type generic
function, passing it the original generic function's first argument.
Now let's redefine our foo generic function to have the new method
combination, and a method on handle-content-type:
(defgeneric foo (request)
(:generic-function-class accept-generic-function)
(:method-combination content-negotiation/or))
(defmethod handle-content-type ((x string))
(format t "Content-Type: ~A~%" *actual-content-type*))
and now, finally, we can try it all out:
SPECIALIZABLE> (foo "text/plain,text/html;q=0.9,*/*;q=0.8")
Content-Type: text/plain
"Foo"
SPECIALIZABLE> (foo "text/turtle,application/rdf+xml;q=0.9")
Content-Type: text/turtle
"@prefix foo: <http://example.org/ns#> .
@prefix : <http://other.example.org/ns#> .
foo:bar foo: : ."
SPECIALIZABLE> (foo "audio/mp3")
406
OK, but by what magic do these accept-specializer objects exist and
function? I wrote a paper about that, with Jan Moringen and David
Lichteblau: as part of my ongoing open access experimentation, the
version we submitted to the European Lisp Symposium is viewable
at Goldsmiths' e-prints repository
or on arXiv. The ELS Chairs have
just announced a deadline extension, so there's still time (until
March 23) for anyone to submit technical papers or abstracts for
tutorials and demonstration sessions: please do, and I hope to see
many of my readers there.
Just because I'm attending mobile world congress doesn't mean that everything else stops. It's the end of the month, so it must be time to release sbcl. This month's is a little unsatisfying, because we've only achieved one of the two things I'd hoped for: we've been cautious and conservative after last month's landing of the new register allocator, but we haven't sorted out what's going on to cause the less active architectures to fail to build. There are some workarounds that have been mooted; for one reason and another no-one has had the time to check whether they actually work, and while there's partial progress on identifying the root cause of the build failure on sparc it is only partial.
Nevertheless, minor architectures have been broken before, and no-one
particularly benefits from not releasing, so 1.1.16 it is. Actually
making the release is a little more challenging than usual: I aim to
release by the end of the month, and in practice that means it must be
done today, 28th February. However, this is the day that I am
returning from Barcelona, so I am less in control of laptop power and
connectivity than usual for a release day. And to add to the
challenge, I am trying this time to address the valid complaints that
the binaries built on my laptop don't actually run on released
versions of Linux, thanks to the change in the semantics of memcpy
(glibc changed the implementation in its version 2.14 to exploit the
freedom given to return undefined results if the source and
destination overlap) and the behaviour of the linker and versioned
symbols.
So over breakfast I dusted off my
squeeze chroot (that
doesn't sound dodgy at all), and tried to work out how to get a
runnable version of SBCL in there at all (answer: build using
clisp and link to the chroot's libc). At
lunchtime, I used the café's wireless to check for any last-minute
changes, and in the airport I found a power socket, so I started the
release build. Of course it didn't finish before the gate opened,
and in any case I wasn't going to chance uploading sbcl binaries over
the free airport wifi (15 minutes, woo!)
I've performed some release stunts before. SBCL 0.9 was released by William Harold Newman and simultaneously announced by me at the first European Common Lisp Meeting in Amsterdam in 2005. Last year, I released SBCL 1.1.8 “live” as part of a lightning talk at the European Lisp Symposium in Madrid. But I think this is the first time that an SBCL release was even partially effected from the air. Next stop, space?
I received notification yesterday that SBCL was accepted as a “mentoring organization” to Google's Summer of Code 2014 programme. What this means is that eligible students can think about applying to be mentored by members of the SBCL team to work on a development project – and to be paid a stipend for that work.
The next steps for students are:
- get involved with the community: join
#lispand#sbclon the freenode IRC network; read thesbcl-develmailing list (e.g. atgmane.lisp.steel-bank.devel; have a go at some of the bugs marked as ‘easy’ - look at the existing list of project ideas, and see if any of those ideas would form a good basis for a project that would sustain your interest for three months or so.
- read Paul Khuong's essay on getting started with SBCL from last year: it is still absolutely applicable to this year's programme, or indeed getting into SBCL hacking independently.
The period for student applications to be mentored as part of SBCL's participation is from 10th March until 21st March 2014; for best results, get engaged with the community and potential mentors well before the cutoff point.
Last year two projects were funded, and both completed successfully, even if merging them into the mainline is/was slower than one might like. I'm looking forward to seeing what this year brings!
Once upon a time, I wrote two blog entries about precompiling the dispatch for generic functions in order to improve the responsiveness at application startup, and obviously planned a third but didn't get around to writing it. Some time later, I asked the lazyweb about it, and unfortunately this time didn't get anything much back. On further reflection, I think I was going to discuss a couple of additional technical points.
First of all, there's the question about having this kind of precompilation on all the time; wouldn't it be nice if generic functions were always at their most efficient, ready to be called? Well, yes, but what we actually want is for functions to be at their most efficient when we want to call them, and we don't particularly care at other times. Why draw that distinction? Well, when we write code that uses generic functions, it is usually of the form:
(defgeneric foo (x y))
(defmethod foo ((x t) (y t)) ...)
(defmethod foo ((x integer) (y integer)) ...)
(defmethod foo ((x rational) (y float)) ...)
a sequence of method definitions; sometimes contiguous, as above;
often distributed among various files.
loading
such code will execute the
defmethod
forms in series. And each of those executions will call
add-method,
changing the generic function's methods, so any aggressive dispatch
precompilation scheme will kick in at every defmethod. That would
be bad enough, being O(N) in the number of methods, but it's
actually worse than that: the amount of work involved in
precompilation will tend to be O(N) in the number of methods, or
in the number of concrete classes applicable to those methods, so
there's O(N2) or worse behaviour from having
precompilation active all the time. SBCL is
routinely mocked for having slow-loading FASL files (originally, FASL
probably stood for FASt Load; we don't advertise that much); expensive
and poorly-scaling computations at load-time probably won't win us any
extra friends. (Though having written that, I now wonder if recording
changed generic functions using the dependent-update protocol, and
hooking load or asdf:load-system to precompile after loading a
whole file or system, might be a tasteful compromise).
Secondly, there's the detail of exactly how to pre-fill the cache for a given generic function (given that its specializers are mostly or entirely classes). The simplest strategy, of filling the cache with exactly those classes used as specializers, fails as soon as abstract or protocol classes are used to organize the implementation of the generic function. The next simplest, which is to fill the cache with all possible subclasses of specializers at all argument positions, well, just reading that should set alarm bells ringing – it might not be too problematic for generic functions with one argument, but the cross-product effect of multiple arguments will probably cause the implementation to collapse under its own weight into a virtual black hole. It might be that the best approach is to allow the user to specify an exact set of classes: and to allow the user to introspect a running system to find out which class combinations have actually been seen and hence cached in a given session.
In fact, SBCL itself depends on a particular, specific version of
this. The generic function
print-object
is used for printing almost everything; even without user
specialization, it is called whenever a
structure-object
or
standard-object
needs to be output to any stream. Users can write methods on it,
though, and that then invalidates any previous precomputed dispatch
information. But there are times when it's really important that
print-object just work, without any kind of extra computation to go
on: in particular, when the debugger needs to inform the user that the
Lisp is running out of storage space (heap or stack), it's pretty
important that that reporting can happen without using more heap or
stack than necessary. So for print-object, we never reset the cache
state to empty; it is always prefilled with entries for
control-stack-exhausted, binding-stack-exhausted,
alien-stack-exhausted, heap-exhausted-error and
restart
for its first argument. (This strategy only works if there are no
specializations of the second argument to print-object anywhere in
the system; there's no good reason for a user to try to specialize the
second argument in any case, so we emit a warning if they do that and
hope that they read and learn from it.)
I got a few responses to my call for use cases for generalized specializers; I'll try to summarize them in this post. Before I do, it's perhaps worth noting that the work on generalized specializers that Jim Newton and I did was written up at about the same time as Charlotte Herzeel, Jorge Vallejos, Theo D'Hondt and Pascal Costanza's work on filtered dispatch, and so our Custom Specializers in Object-Oriented Lisp paper doesn't refer to it. I'll talk more about filtered dispatch in a later post, when I tie all these threads together, but for those who aren't aware of it it's worth looking at, along with ContextL for dispatch that varies based on dynamic program state.
Meanwhile, some other ideas for extended specializers: James Anderson suggested duck typing, and I think working along similar lines Patrick Stein thought of specializers that could dispatch on the dimensions of array arguments (or length of sequence arguments). That feels to me as though there should be a fairly compelling use case, but the toy example of
(defmethod cross-product ((x (length 3)) (y (length 3)))
...)
doesn't generalize. I suppose there might be an example of selecting particular numerical algorithms based on overall matrix dimensions or properties, something like
(defmethod invert ((x (total-size> 1000000000)))
... invert big matrix ...)
(defmethod invert ((x (total-size<= 1000000000)))
... invert small matrix ...)
but it doesn't feel concrete yet.
On the other hand, just about everyone's first response to the
question (Jan Moringen, and the crowded wisdom of #lisp IRC) was
pattern specializers, usually through regular expressions or
optima in particular; one example
concrete use case given was to dispatch among handlers for urls. This
is a very interesting case; I first considered this in the early days
of extended specializers, and indeed
mop-27.impure.lisp
from the SBCL test suite captures one other use case, in a (toy)
simplifier for arithmetic expressions, redolent of implementations of
symbolic differentiation from a bygone age. At the time, I took that
example no further, both because I didn't have a real use case, and
also because I didn't fancy writing a full-strength pattern matching
engine; now that optima exists, it's probably worth revisiting the
example.
In particular, it's worth considering how to handle capturing of pattern variables. To continue with the toy simplifier, the existing dispatch and specializer implementation would allow one to write
(defmethod simplify1 ((p (pattern (+ x 0))))
(cadr p))
but what would be really neat and convenient would be to be able to write
(defmethod simplify1 ((p (pattern (+ x 0))))
x)
and in order to do that, we need to intercede in the generation of the actual method function in order to add bindings for pattern variables (which, helpfully, optima can tell us about).
The awkwardness in terms of the protocol – beyond the
problems with metaprogramming at compile-time in the first place
– is that
make-method-lambda
operates in ignorance of the specializers that will be applied to the
method. In fact, this was the root cause of a
recently-reported SBCL bug:
SBCL itself needs to communicate the name and method lambda list from
defmethod
to make-method-lambda, and has no other way of doing that than
special variables, which weren't being cleared to defend against
nested calls to make-method-lambda through code-walking and
macroexpansion.
But make-method-lambda is the function which generates the method
body; it is exactly the function that we need to extend or override in
order to do the desired automatic matching. So how can we expose this
to the metaprogrammer? We can't change the signature of
make-method-lambda; it might seem obvious to extend it by adding
&optional
arguments, but that changes the signature of the generic function and
would break backwards compatibility, as methods must accept the same
number of optional arguments as their generic function does;
similarly, adding keyword arguments to the generic function doesn't
work.
We could export and document the special variables that we ourselves
use to propagate the information; in some ways that's cleanest, and
has the virtue of at least having been tested in the wild. On the
other hand, it feels unusual, at least in the context of the
metaobject protocol; usually, everything of interest is an argument to
a protocol function. So, we could define a new protocol function, and
have make-method-lambda default to trampolining to it (say,
make-method-lambda-with-specializer-specifiers; the basic idea,
though not the horrible name, is due to Jan Moringen). But we'd need
to be careful in doing that; there is some implementation-specific
logic deep in PCL that performs extra optimizations to methods (the
fast-method calling convention) if the system detects that only the
standardized methods on make-method-lambda are applicable to a
particular call; if we add any extra metaobject protocol functions in
this area, we'll need to make sure that we correctly update any
internal logic based on detecting the absence of metaprogrammer
overrides or extensions...
I received a couple of points in feedback regarding
protoypes with multiple dispatch. Firstly, from
Pascal Costanza, the observation that there's
already a prototype-based dispatch system present in the
quasi-standard CL MOP; the key is to view all the prototype objects as
singletons, and to use introspection to manage delegation and the
class-prototype
as the actual object. Thus (any mistakes are mine, not Pascal's):
(defun clone (o)
(let* ((scs (sb-mop:class-direct-superclasses (class-of o)))
(new (make-instance 'standard-class :direct-superclasses scs)))
(sb-mop:finalize-inheritance new)
(sb-mop:class-prototype new)))
(defun add-delegation (o d)
(let ((scs (sb-mop:class-direct-superclasses (class-of o))))
(reinitialize-instance (class-of o)
:direct-superclasses (list* (class-of d) scs))))
I don't think that this works in quite the same way as a traditional prototype-based system, mind you: here, a cloned object inherits all the behaviours provided by delegation, but not the behaviours from the cloned object itself. It's pretty close, though, and might help those to whom all this is new (but who are intimately familiar with the CLOS MOP – hm, actually, the intersection of those two sets might be a little small) get a bit of a handle on this.
Secondly, Lee Salzman was kind enough to get in touch, and we had a
conversation about his thesis and his reflections on that work. I'll
paraphrase, so again any misrepresentation is mine, but regarding the
question at the end of my
previous post about the
semantics of redefinition, Lee was quite clear that the expectation
was that previously-cloned objects should retain their previous
behaviour, even if the original object is later updated (in prototypes
and multiple dispatch terms, even if the original method is
redefined). In other words, the ??? is indeed expected by
prototype-oriented programmers to be (FOO[1] /B/).
Lee also said that, in his subsequent experience, he has come to believe that class-based systems are a necessity – particularly in image-based systems (where there is a persistent world). He's happy with prototypes as a mechanism in a world with static programme descriptions, where you can just edit the source code, then compile and run the programme, but believes that directly modifying running programmes makes classes or some equivalent abstraction necessary. I'm not sure I completely understand this point (though I'm fairly convinced by now that I don't much like the semantics of method redefinition in a world with long-lived objects), but I'm still waiting for a good example to highlight the advantages of prototype-oriented programmes.
Meanwhile, what does this imply for the implementation of prototypes
with multiple dispatch within the extended CLOS metaobject protocol?
Defining a new method specialized on an must override any existing
behaviour for that object, but must leave unchanged the previous
behaviour for any clones; that therefore implies that the generic
function cannot discard the old method, as it must remain applicable
to any clones. The consequences of this include: two prototype
specializers, specialized on the same object, must not be considered
to be the same specializers (otherwise the standard semantics of
method definition would replace the old method with the new); and that
the specializers must be annotated with the method that they belong to
(so that it is possible to compute for a given specializer and
argument whether that argument is acceptable to the specializer,
remembering that the acceptability of an object to a prototype
specializer in this world is primarily a function of the object
itself). One piece of good news: the CLOS MOP already provides a
mechanism for associating specializers with methods, through the
specializer-direct-methods
generic function, so that's at least some of the battle.
All of this merits a fuller description, a reference implementation, and some example code using it. I'm working on the first two, aiming to top up my all-important publications list by presenting at some conferences (and also helping to justifying my attendance); I'd love to hear about ideas for the third...
On New Year's Day (did I have nothing better to do?) I asked the wider world real life uses of non-standard method selection, and I hinted that I had an real-life example of my own. This post does not discuss that example.
Instead, I'm going to discuss my limited understanding of another non-standard (at least, non-CLOS-standard) method selection system, and demonstrate what its use looks like in my current development world. I'm talking about a prototype-based object system: specifically, a mostly-faithful reimplementation of the Prototypes with Multiple Dispatch [1,2] system found in Slate and described by Lee Salzman and Jonathan Aldrich. I'll try to introduce the semantics as I understand them to an audience used to class-based multiple dispatch, but I'm left with some questions that I don't know how to answer, not being used to programming in this way myself.
So, first, what's going on? Well, the proper answer might be to read the linked papers, which have a relatively formal specification of the semantics, but the high-level idea could perhaps be summarised as finding what happens when you try to support prototype-based object systems (where the normal way to instantiate an object is to copy another one; where objects implement some of their functionality by delegating to other objects; and where single-dispatch methods are stored in the object itself) and multiple dispatch systems (where methods do not have a privileged receiver but dispatch on all of their arguments) simultaneously. The authors found that they could implement some reasonable semantics, and perform dispatch reasonably efficiently, by storing some dispatch metainformation within the objects themselves. The example code, involving the interactions between fish, healthy sharks and dying sharks, can be translated into my extended-specializer CL as:
(defpvar /root/ (make-instance 'prototype-object :delegations nil))
(defpvar /animal/ (clone /root/))
(defpvar /fish/ (clone /root/))
(defpvar /shark/ (clone /root/))
(defpvar /healthy-shark/ (clone /root/))
(defpvar /dying-shark/ (clone /root/))
(add-delegation /fish/ /animal/)
(add-delegation /shark/ /animal/)
(add-delegation /shark/ /healthy-shark/)
(defgeneric encounter (x y)
(:generic-function-class prototype-generic-function))
(defmethod encounter ((x /fish/) (y /healthy-shark/))
(format t "~&~A swims away~%" x))
(defmethod encounter ((x /fish/) (y /animal/))
x)
(defgeneric fight (x y)
(:generic-function-class prototype-generic-function))
(defmethod fight ((x /healthy-shark/) (y /shark/))
(remove-delegation x)
(add-delegation x /dying-shark/)
x)
(defmethod encounter ((x /healthy-shark/) (y /fish/))
(format t "~&~A swallows ~A~%" x y))
(defmethod encounter ((x /healthy-shark/) (y /shark/))
(format t "~&~A fights ~A~%" x y)
(fight x y))
(compare figures 4 and 7 of
[1]; defpvar
is secretly just
defvar
with some extra debugging information so I don't go crazy trying to
understand what a particular #<PROTOTYPE-OBJECT ...> actually is.)
Running some of the above code with
(encounter (clone /shark/) (clone /shark/))
prints
#<PROTOTYPE-OBJECT [/HEALTHY-SHARK/, /ANIMAL/] {10079A8713}> fights
#<PROTOTYPE-OBJECT [/HEALTHY-SHARK/, /ANIMAL/] {10079A8903}>
and returns
#<PROTOTYPE-OBJECT [/DYING-SHARK/, /ANIMAL/] {10079A8713}>
(and I'm confident that that's what is meant to happen, though I don't really understand why in this model sharks aren't fish).
The first question I have, then, is another lazyweb question: are there larger programs written in this style that demonstrate the advantages of prototypes with multiple dispatch (specifically over classes with multiple dispatch; i.e. over regular CLOS). I know of Sheeple, another lisp implementation of prototype dispatch, probably different in subtle or not-so-subtle ways from this one; what I'm after, though, probably doesn't exist: if there's no easy way of using prototype dispatch in Lisp, it won't be used to solve problems, and some other way will be used instead (let's call that the computer programmer's weak version of the Sapir-Whorf hypothesis). What's the canonical example of a problem where prototype-based object systems shine?
The second question I have is more technical, and more directly related to the expected semantics. In particular, I don't know what would be expected in the presence of method redefinition, or even if method redefinition is a concept that can make sense in this world. Consider
(defpvar /a/ (clone /root/))
(defgeneric foo (x)
(:generic-function-class prototype-generic-function))
(defmethod foo ((x /a/)) `(foo[1] ,x))
(defpvar /b/ (clone /a/))
(foo /a/) ; => (FOO[1] /A/)
(foo /b/) ; => (FOO[1] /B/)
(defmethod foo ((x /a/)) `(foo[2] ,x))
(foo /a/) ; => (FOO[2] /A/)
(foo /b/) ; => ???
What should that last form return? Arguments from the
prototype-oriented world would, I suspect, lead to the desired return
value being (FOO[1] /B/), as the redefinition of the method on foo
specialized to /a/ is completely irrelevant to /b/. This is my
reading of the semantics described in
[1], for what
it's worth. Arguments from the world of generic functions and
expected behaviour would probably argue for (FOO[2] /B/), because
redefining a method is an action on a generic function, not an action
on a set of application objects. And the argument of my
implementation in practice (at present, subject to change) is to
signal
no-applicable-method,
because method redefinition is the successive removal of the old
method and addition of the new one, and removal of the old method of
the generic function affects dispatch on all the objects, whereas
adding the new one affects dispatch on just /a/.
This is probably not news to anyone reading this, but: SLIME has moved its primary source repository to github.
One of my projects, swankr
(essentially, a SLIME for R, reusing most
of the existing communication protocol and implementing a SWANK
backend in R, hence the name), obviously depends on SLIME: if nothing
else, the existing instructions for getting swankr up and running
included a suggestion to get the SLIME sources from common-lisp.net
CVS, which as Zach says is
a problem that it's nice no longer to have. (Incidentally, Zach is
running a survey –
direct link
– to assess possible effects of changes on the SLIME userbase.)
So, time to update the instructions, and in the process also
- hoover up any obvious patches from my inbox;
- improve the startup configuration so that the user need do no
explicit configuration beyond a suitable entry in
slime-lisp-implementations; - update the
BUGS.organdTODO.orgfiles for the current reality.
That's all safely checked in and pushed to the many various locations which people might think of as the primary swankr repository. But those org-mode files are exported to HTML to produce the minimal swankr web presence, and the script that does that was last run with org-mode version 7.x, while now, in the future, org-mode is up to version 8 (and this time the change in major version number is definitely indicative of non-backwards-compatible API changes).
This has already bitten me. The principles of reproducible research are good, and org-mode offers many of the features that help: easily-edited source format, integration with a polyglossia of programming languages, high-quality PDF output (and adequate-quality HTML output, from the same sources) – I've written some technical reports in this style, and been generally happy with it. But, with the changes from org-mode 7 to org-mode 8, in order to reproduce my existing documents I needed to make not only (minor) source document changes, but also (quite major) changes to the bits of elisp to generate exported documents in house style. Reproducible research is difficult; I suppose it's obvious that exact reproduction depends on exact software versions, platform configurations and so on – see this paper, for example – but how many authors of supposedly reproducible research are actually listing all the programs, up to exact versions of dynamically-linked libraries they link to, used in the preparation and treatment of the data and document?
In any case, the changes needed for swankr are
pretty minor,
though I was briefly confused when I tried
org-html-export-as-html first (and no output was
produced, because that's the new name for exporting to an HTML
buffer rather than an HTML file. The
swankr website should now
reflect the current state of affairs.
A year or so ago, I wrote a couple of blog entries on precompiling
discriminating functions for generic functions, both given
mostly class-based dispatch
and also when
most of the methods were specialized on individual objects
(i.e. methods with specializers of class
eql-specializer).
I signed off the second entry with
Next up, unless I've made further oversights which need correction: automating this process, and some incidental thoughts.
and of course never got back to this topic. Now it's over a year later, and I can no longer remember either my incidental thoughts, which I'm sure were fascinating, nor my strategy for automating this (because this was an attempt to address an actual user need, in – if I remember correctly – a CL implementation of protobuf). Suggestions for what I might have been thinking at the time gratefully received.
Write more: you know it makes sense.
How meta. To maintain my progress on my
new year's resolution, I have written some code (*gasp!*)
– yes, that counts as writing. And what does that code do? Why, it
makes me more efficient at highly hyperlinked blogging: it is a
certain amount of fairly trivial and mildly tedious elisp, which
allows the easy insertion of markdown markup to create links to
various authoritative sources of information about Lisp. Well, OK, to
the Hyperspec and the MOP dictionary, but as an implementor that's all
I really need, right? So, now I can talk about
compute-effective-method
or
make-method-lambda
and my eager readers can be taken to the relevant documentation at the
speed of thought.
Questions that arose during the process:
- why are all the fake packages in
hyperspec.elcreated with(make-vector 67 0)? - has anyone in the 23 years since
AMOP
was published ever been glad that the MOP standardizes the
extract-lambda-listandextract-specializer-namesfunctions? (Fun fact: SBCL also hasextract-parametersandextract-required-parametersfunctions, unexported and unused.)
There are times when being in control of the whole software stack is a mixed blessing.
While doing investigations related to my
previous post,
I found myself wondering what the arguments and return values of
make-method-lambda
were in practice, in SBCL. So I did what any
self-respecting Lisp programmer would do, and instead of following
that link and decoding the description, I simply ran
(trace sb-mop:make-method-lambda), and then ran my defmethod as
normal. I was half-expecting it to break instantly, because the
implementation of trace encapsulates named functions in a way that
changes the class of the function object (essentially, it wraps the
existing function in a new anonymous function; fine for ordinary
functions, not so good for generic-function objects), and I was
half-right: an odd error occurred, but after trace printed the
information I wanted.
What was the odd error? Well, after successfully calling and
returning from make-method-lambda, I got a no-applicable-method
error while trying to compute the applicable methods
for... make-method-lambda. Wait, what?
SBCL's CLOS has various optimizations in it; some of them have been
documented in the
SBCL Internals Manual, such as
the clever things done to make slot-value fast, and specialized
discriminating functions. There are plenty more that are more opaque
to the modern user, one of which is the “fast method call”
optimization. In that optimization, the normal calling convention for
methods within method combination, which involves calling the method's
method-function with two arguments – a list of the arguments passed
to the generic function, and a list of next methods – is bypassed,
with the fast-method-function instead being supplied with a
permutation vector (for fast slot access) and next method call (for
fast call-next-method) as the first two arguments and the generic
function's original arguments as the remainder, unrolled.
In order for this optimization to be valid, the call-method calling
convention must be the standard one – if the user is extending or
overriding the method invocation protocol, all the optimizations based
on assuming that the method invocation protocol might be invalid.
We have to be conservative, so we need to turn this optimization off
if we can't prove that it's valid – and the only case where we can
prove that it's valid is if only the system-provided method on
make-method-lambda has been called. But we can't communicate that
after the fact; although make-method-lambda returns initargs as well
as the lambda, an extending method could arbitrarily mess with the
lambda while returning the initargs the system-provided method
returns. So in order to find out whether the optimization is safe, we
have to check whether exactly our system-provided method on
make-method-lambda was the applicable one, so there's an explicit
call to compute-applicable-methods of make-method-lambda after
the method object has been created. And make-method-lambda being
traced and hence not a generic-function any more, it's normal that
there's an error. Hooray! Now we understand what is going on.
As for how to fix it, well, how about adding an encapsulations slot
to generic-function objects, and handling the encapsulations in
sb-mop:compute-discriminating-function?
The encapsulation implementation as it currently stands is fairly
horrible, abusing as it does special variables and chains of closures;
there's a fair chance that encapsulating generic functions in this way
will turn out a bit less horrible. So, modify
sb-debug::encapsulate, C-c C-c, and package locks strike. In
theory we are meant to be able to unlock and continue; in practice,
that seems to be true for some package locks but not others.
Specifically, the package lock from setting the fdefinition from a
non-approved package gives a continuable error, but the ones from
compiling special declarations of locked symbols have already taken
effect and converted themselves to run-time errors. Curses. So,
(mapcar #'unlock-package (list-all-packages)) and try again; then,
it all goes well until adding the slot to the generic-function class
(and I note in passing that many of the attributes that CL specifies
are generic-function SBCL only gives to standard-generic-function
objects), at which point my SLIME repl tells me that something has
gone wrong, but not what, because no generic function works any more,
including print-object. (This happens depressingly often while
working on CLOS).
That means it's time for an SBCL rebuild, which is fine because it
gives me time to write up this blog entry up to this point. Great,
that finishes, and now we go onwards: implementing the functionality
we need in compute-discriminating-function is a bit horrible, but
this is only a proof-of-concept so we wrap it all up in a labels and
stop worrying about 80-column conventions. Then we hit C-c C-c and
belatedly remember that redefining methods involves removing them from
their generic function and adding them again, and doing that to
compute-discriminating-function is likely to have bad consequences.
Sure enough:
There is no applicable method for the generic function
#<STANDARD-GENERIC-FUNCTION COMPUTE-DISCRIMINATING-FUNCTION (1)>
when called with arguments
(#<STANDARD-GENERIC-FUNCTION NO-APPLICABLE-METHOD (1)>).
Yes, well. One (shorter) rebuild of just CLOS later, and then a few more edit/build/test cycles, and we can trace generic functions without changing the identity of the fdefinition. Hooray! Wait, what was I intending to do with my evening?
Some time ago (call it half a decade or so), Jim Newton of Cadence and I did some work on extensible specializers: essentially coming up with a proof-of-concept protocol to allow users to define their own specializers with their own applicability and ordering semantics. That's a little bit vague; the concrete example we used in the writeup was a code walker which could warn about the use of unbound variables (and the non-use of bindings), and which implemented its handling of special forms with code of the form:
(defmethod walk ((expr (cons (eql 'quote))) env call-stack)
nil)
(defmethod walk ((var symbol) env call-stack)
(let ((binding (find-binding env var)))
(if binding
(setf (used binding) t)
(format t "~&unbound: ~A: ~A~%" var call-stack))))
(defmethod walk ((form (cons (eql 'lambda))) env call-stack)
(destructuring-bind (lambda lambda-list &rest body) form
(let* ((bindings (derive-bindings-from-ll lambda-list))
(env* (make-env bindings env)))
(dolist (form body)
(walk form env* (cons form call-stack)))
(dolist (binding bindings)
(unless (used (cdr binding))
(format t "~&unused: ~A: ~A~%" (car binding) call-stack))))))
The idea here is that it's possible to implement support in the walker
for extra special forms in a modular way; while this doesn't matter
very much in Common Lisp (which, famously, is not dead, just smells
funny), in other languages which have made other tradeoffs in the
volatility/extensibility space. And when I say “very much” I mean it:
even SBCL allows extra special forms to be loaded at runtime; the
sb-cltl2 module includes an implementation of compiler-let, which
requires its own special handling in the codewalker which is used in
the implementation of CLOS.
So modularity and extensibility is required in a code walker, even in
Common Lisp implementations; in
Cadence Skill++ it might
even be generally useful (I don't know). In SBCL, the extensibility
is provided using an explicit definer form; sb-cltl2 does
(defun walk-compiler-let (form context env)
#1=#<implementation elided>)
(sb-walker::define-walker-template compiler-let walk-compiler-let)
and that's not substantially different from
(defmethod sb-walker:walk ((form (cons (eql 'compiler-let))) context env)
#1#)
So far, so unexpected, for Lisp language extensions at least: of
course the obvious test for a language extension is how many lines
of code it can save when implementing another language extension.
Where this might become interesting (and this, dear lazyweb, is where
you come in) is if this kind of extension is relevant in application
domains. Ideally, then, I'm looking for real-life examples of
patterns of selecting ‘methods’ (they don't have to be expressed as
Lisp methods, just distinct functions) based on attributes of objects,
not just the objects' classes. The walker above satisfies these
criteria: the objects under consideration are all of type symbol or
cons, but the dispatch partly happens based on the car of the
cons – but are there examples with less of the meta nature about
them?
(I do have at least one example, which I will keep to myself for a little while: I will return to this in a future post, but for now I am interested in whether there's a variety of such things, and whether the generalization of specializer metaobjects is capable of handling cases I haven't thought of yet. Bonus points if the application requires multiple dispatch and/or non-standard method combination.)
One of the potential advantages of this new wiki/blog setup is that I should be able to refer easily to my notes in my blog. It's true that the wiki-like content will change, whereas a mostly-static blog entry will naturally refer to the content of the wiki as it is at the point of blogging; in theory I should be able to find the content at the time that the link was made through a sufficiently advanced use of the version control system backing the ikiwiki installation, and in practice the readers of the blog (if any) are likely to follow (or not) any links within a short time-window of the initial publication of any given entry. So that shouldn't prove too confusing.
In order to test this, and to provide some slightly-relevant content
for anyone still reading this on
planet lisp: I've transferred my
non-actionable notes from my sbcl org-mode file to an
sbcl wiki section. This new setup gets heaps of bonus
points if someone out there implements the development projects listed
there as a result of reading this post, but even if not, it's a useful
decluttering...