Another term, another cycle of Algorithms & Data Structures.
This year I am teaching the entire two-term course by myself, compared with last academic year when I co-taught with another member of staff. The change brings with it different challenges; notably that I am directly responsible for more content. Or in this case, more multiple-choice quizzes!
This term, the students have been given nine multiple-choice quizzes, of which four are new content and five are revisions of last year's quizzes. The revisions are mostly to add more variety to particular question types – finding axes of generalization that I hadn't exploited last time – and more (and more punishing) distractor answers, so that students cannot game the system too easily.
Some of this is my own adaptation to behaviours I see in the student body; for example, one behaviour I started seeing this year was the habit of selecting all the answers from a multiple-answer multiple-choice question. This was probably a reaction itself to the configuration of the quiz not telling the students the right answer after the attempt, but merely whether they had got it right or wrong; the behaviour of the quiz engine (the Moodle quiz activity) was for each selected answer to indicate the correctness status, and so students were exploiting this to see the right answers. This was not in itself a problem – there were enough questions that in the student's next attempts at the quiz they were unlikely to see the same questions again – but it was being used as a substitute for actually thinking and working at the problem, and so this was a behaviour that I wanted to discourage. The next quiz, therefore, I adapted so that it had many single-answer multiple choice with many more distractor answers than usual: seven or eight, rather than the usual three or so. (I do not know whether the message got through.)
The new quizzes address some weaknesses I saw in the student body of knowledge last year, and indeed have seen in previous years too: a general lack of a robust mental model (or possibly “notional machine” of computation. To try to address this, I taught a specific dialect of pseudocode in the introductory lecture (nothing particularly esoteric; in fact, essentially what is provided by the algorithmicx LaTeX package). I then also wrote a small interpreter in emacs lisp for that pseudocode language (with a s-expression surface syntax, of course) and a pretty-printer from s-expressions to HTML, so that I could randomly generate blocks of pseudocode and ask students questions about them: starting with the basics, with sequences of expressions, and introducing conditionals, loops, nested loops, and loops with break.
The results of this quiz were revealing; at the start of the cycle, many students were unable to answer questions about loops at all – perhaps unsurprising as the complete description of the loop syntax was only given to the students in the second lecture. Even those who had intuited the meaning of the loop form that I was using had difficulty with nested loops, and this difficulty remained evident all the way to the end of the quiz period. (By way of comparison, students were able to deal with quite complicated chains of conditionals with not much more difficulty than straight-line pseudocode.) It will be very interesting to see whether the reforms and extensions we have put in place to our first-year curriculum will make a difference to this particular task next year.
Of course, once I had the beginnings of a pseudocode interpreter and pretty-printer, I then got to use it elsewhere, to the point that it has now grown (almost) enough functionality to warrant a static analyser and compiler. I'm resisting, because fundamentally it's about generating questions for multiple-choice quizzes, not about being a language for doing anything else with – but with an even fuller model for the computation, I could make something akin to Paul F. Dietz' Common Lisp random tester (still active after 15 years) which would probably have helped me spot a mistake I made when generating multiple-choice answers to questions about recursive algorithms, of the form “which of the following expressions replaces X in order to make this function return the sum of its two arguments?”.
As well as the quizzes, the students have done six automatically-marked lab exercises and one technical peer-assessment. My direct involvement in assessment after setting all of these exercises has been limited to checking that the results of the peer-assessment are reasonable, by examining cases with outliers at a rate of maybe 6 minutes per student. Indirect involvement includes delivering lectures, answering questions face-to-face and on the forum, system administration, and writing code that writes code that writes summary feedback reports; this is probably a higher-value use of my time for the students than individualized marking; in that time, the students have received, on average: right-or-wrong judgments on 330 quiz questions (many of which have more than one possible right answer); 45 individual judgments on a moderately open algorithmic task; 50 marks and feedback on programming tasks; and a gentle helping of encouragement and sarcasm, in approximately equal measure, from me.
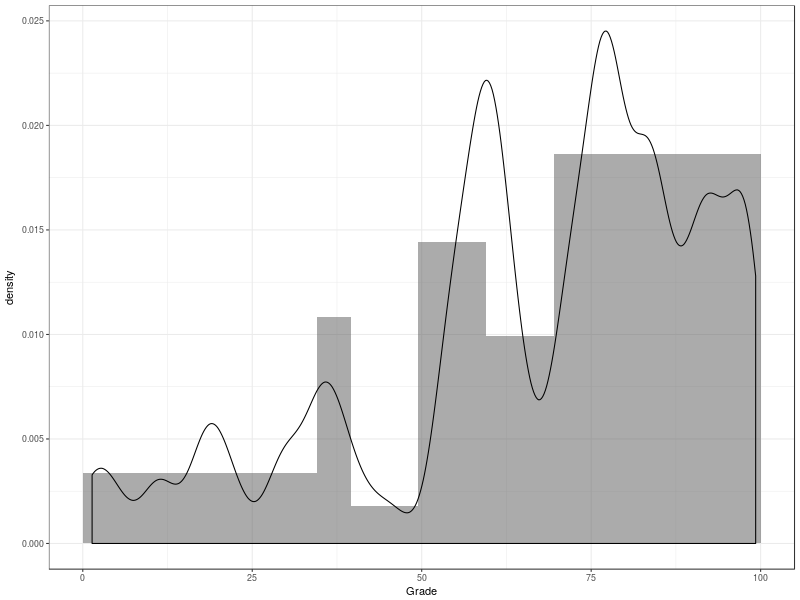
The coursework marks are encouraging; there are a cluster of students at the top, and while the lower tail is disappointingly substantial it is artificially enhanced by a number of students who have (for whatever reason) dropped out. Limiting the analysis to those students who missed at most one assessment gives a more pleasing distribution; almost no-one who attempted everything received a failing mark, though I should temper my satisfaction with that by saying that I need to be careful that I'm not simply giving credit for being able to show up. (There are also some marks from this picture in the middle range, 50-70, which are withheld while allegations of plagiarism and/or collusion are resolved.)
And now, as I write, it is the last working day before term starts
again, when the students return to find this term's lovingly
prepared hastily assembled activities. Onward!