This portion of the ikiwiki installation is for notes organized as a blog, with more permanent observations recorded statically.
I'm on holiday! And holidays, as seems to be my usual, involve trains!
I was on a train yesterday, wondering how I could possibly fill two hours of leisure time (it's more straightforward these days than a few years ago, when my fellow travellers were less able to occupy their leisure time with books), when help came from a thoroughly unexpected quarter: I got a bug report for swankr.
I wrote swankr nine years ago, mostly
at ISMIR2010. I was about to start
the
Teclo phase
of my ongoing adventures, and an academic colleague had recommended
that I learn R; and the moment where it all fell into place was when I
discovered that R supported handlers and restarts: enough that writing
support for slime's SLDB was a lower-effort endeavour than learning
R's default debugger. I implemented support for the bits of slime
that I use, and also for displaying images in the REPL -- so that I
can present lattice objects as thumbnails of the rendered graph, and
have
the
canned demo of
adding two of them together to get a combined graph: generates “oo”
sounds at every outing, guaranteed! (Now that I mostly use ggplot2,
I need to find a new demo: incrementally building and styling a plot
by adding theme, scale, legend objects and so on is actually useful
but lacks a wow factor.)
SLIME works by exchanging messages between the emacs front-end and the backend lisp; code on the backend lisp is responsible for parsing the messages, executing whatever is needed to support the request, and sending a response. The messages are, broadly, sexp-based, and the message parsing and executing in the backends is mostly portable Common Lisp, delegating to implementation-specific code for specific implementation-specific support needed.
“Mostly portable Common Lisp” doesn't mean that it'll run in R. The R
code is necessarily completely separate, implementing just enough of a
Lisp reader to parse the messages. This works fine, because the
messages themselves are simple; when the front-end sends a message
asking for evaluation for the listener, say, the message is in the
form of a sexp, but the form to evaluate is a string of the
user-provided text: so as long as we have enough of a sexp
reader/evaluator to deal with the SLIME protocol messages, the rest
will be handled by the backend's eval function.
... except in some cases. When slime sends a form to be evaluated
which contains an embedded presentation object, the presentation is
replaced by #.(swank:lookup-presented-object-or-lose 57.) in the
string sent for evaluation. This works fine for Common Lisp backends
– at least provided *read-eval* is true – but doesn't work
elsewhere. One regexp allows us to preprocess the string to evaluate
to rewrite this into something else, but what? Enter cunning plan
number 1: (ab)use backquote.
Backquote? Yes, R has backquote bquote. It also has moderately
crazy function call semantics, so it's possible to: rewrite the string
ob be evaluated to contain unquotations; parse the string into a form;
funcall the bquote function on that form (effectively performing the
unquotations, simulating the read-time evaluation), and then eval
the result. And this would be marvellous except that Philipp Marek
discovered that his own bquote-using code didn't work. Some
investigation later, and the root cause became apparent:
CL-USER> (progn (set 'a 3) (eval (read-from-string "``,a")))
`,a
compare
R> a <- 3; bquote(bquote(.(a)))
bquote(3)
NO NESTED BACKQUOTES?
So, scratch the do.call("bquote", ...) plan. What else is available
to us? It turns out that there's a substitute function, which for
substitute(expr, env)
returns the parse tree for the (unevaluated) expression ‘expr’, substituting any variables bound in ‘env’.
Great! Because that means we can use the regular expression to rewrite the presentation lookup function calls to be specific variable references, then substitute these variable references from the id-to-object environment that we have anyway, and Bob is your metaphorical uncle. So I did that.
The situation is not perfect, unfortunately. Here's some more of the
documentation for substitute:
‘substitute’ works on a purely lexical basis. There is no guarantee that the resulting expression makes any sense.
... and here's some more from do.call:
The behavior of some functions, such as ‘substitute’, will not be the same for functions evaluated using ‘do.call’ as if they were evaluated from the interpreter. The precise semantics are currently undefined and subject to change.
Well that's not ominous at all.
Today, I released sbcl-1.5.0 – with no particular reason for the minor version bump except that when the patch version (we don’t in fact do semantic versioning) gets large it’s hard to remember what I need to type in the release script. In the 17 versions (and 17 months) since sbcl-1.4.0, there have been over 2900 commits – almost all by other people – fixing user-reported, developer-identified, and random-tester-lesser-spotted bugs; providing enhancements; improving support for various platforms; and making things faster, smaller, or sometimes both.
It’s sometimes hard for developers to know what their users think of all of this furious activity. It’s definitely hard for me, in the case of SBCL: I throw releases over the wall, and sometimes people tell me I messed up (but usually there is a resounding silence). So I am running a user survey, where I invite you to tell me things about your use of SBCL. All questions are optional: if something is personally or commercially sensitive, please feel free not to tell me about it! But it’s nine years since the last survey (that I know of), and much has changed since then – I'd be glad to hear any information SBCL users would be willing to provide. I hope to collate the information in late March, and report on any insight I can glean from the answers.
(Don't get too excited by the “success” in the title of this post.)
A brief SBCL RISC-V update this time, as there
have been no train journeys since
the last blog post. Most of what has been
achieved is trivial definitions and rearrangements. We've defined
some
more of the MOVE Virtual Operations that
the compiler needs to be able to move quantities between different
storage classes (from immediate to descriptor-reg, or between
tagged fixnums in descriptor-reg to untagged fixnums in
signed-reg, for example).
We've
defined a debugging printer function,
which wouldn't be needed at this stage except that we're asking the
compiler to print out substantial parts of its internal data
structures. We've reorganized, and not in a desperately good way,
the
definitions of the registers and their storage bases and classes;
this area of code is “smelly”, in that various arguments aren't
evaluate when maybe they should be, which means that some other
structures need to be defined at compile-time so that variables can be
defined at compile-time so that values (in the next form) can be
evaluated at read-time; it's all a bit horrible, and
as Paul said, not friendly to interactive
development. And then a few
more
fairly trivial definitions later,
we are at the point where we have a first trace file from compiling
our very
simple
scratch.lisp file.
Hooray! Here's the assembly code of our foo function:
L10:
VOP XEP-ALLOCATE-FRAME {#<SB!ASSEM:LABEL 1>}
L1:
VOP EMIT-LABEL {#<SB!ASSEM:LABEL 2>}
L2:
VOP EMIT-LABEL {#<SB!ASSEM:LABEL 3>}
L3:
VOP NOTE-ENVIRONMENT-START {#<SB!ASSEM:LABEL 4>}
L4:
L11:
L5:
VOP TYPE-CHECK-ERROR/C #:G0!4[A0] :DEBUG-ENVIRONMENT
{SB!KERNEL:OBJECT-NOT-SIMPLE-ARRAY-FIXNUM-ERROR X}
L12:
byte 50
byte 40
.align 2
L6:
VOP EMIT-LABEL {#<SB!ASSEM:LABEL 7>}
L7:
VOP EMIT-LABEL {#<SB!ASSEM:LABEL 8>}
L8:
VOP NOTE-ENVIRONMENT-START {#<SB!ASSEM:LABEL 9>}
L9:
L13:
L14:
L15:
I hope that everyone can agree that this is a flawless gem of a function.
The next step is probably to start actually defining and using RISC-V instructions, so... stay tuned!
In our first post, I summarized the work of
a few evenings of heat and a few hours on a train, being basically the
boilerplate (parenthesis-infested boilerplate, but boilerplate
nonetheless) necessary to get an SBCL
cross-compiler built. At that point, it was possible to start running
make-host-2.sh, attempting to use the cross-compiler to build the
Lisp sources to go into the initial Lisp image for the new,
target SBCL. Of course, given that all I had
done was create boilerplate, running the cross-compiler was unlikely
to end well: and in fact it barely started well, giving an immediate
error of functions not being defined.
Well, functions not being defined is a fairly normal state of affairs (fans of static type systems look away now!), and easily fixed: we simply define them until they're not undefined any more, ideally with sensible rather than nonsensical contents. That additional constraint, though, gives us our first opportunity to indulge in some actual thought about our target platform.
The routines we have to define include things like functions to return Temporary Names (registers or stack locations) for such things as the lisp return address, the old frame pointer, and the number of arguments to a function: these are things that will be a part of the lisp calling convention, which may or may not bear much relation to the “native” C calling convention. On most SBCL platforms, it doesn't have much in common, with Lisp execution effectively being one large complicated subroutine when viewed from the prism of the C world; the Lisp execution uses a separate stack, which allows us to be sure about what on the stack is a Lisp object and what might not be (making garbage collectors precise on those platforms).
In the nascent RISC-V port, in common with other 32-register ports, these values of interest will be stored in registers, so we need to think about mapping these concepts to the platform registers, documentation of which can be found at the RISC-V site. In particular, let's have a look at logical page 109 (physical page 121) of the user-level RISC-V ISA specification v2.2:
| Register | ABI Name | Description | Saver |
|---|---|---|---|
| x0 | zero | Hard-wired zero | - |
| x1 | ra | Return address | Caller |
| x2 | sp | Stack pointer | Callee |
| x3 | gp | Global pointer | - |
| x4 | tp | Thread pointer | - |
| x5 | t0 | Temporary/Alternate link register | Caller |
| x6-7 | t1-2 | Temporaries | Caller |
| x8 | s0/fp | Saved register/Frame pointer | Callee |
| x9 | s1 | Saved register | Callee |
| x10-11 | a0-1 | Function arguments/return values | Caller |
| x12-17 | a2-7 | Function arguments | Caller |
| x18-27 | s2-11 | Saved registers | Callee |
| x28-31 | t3-6 | Temporaries | Caller |
The table (and the rest of the document) tells us that x0 is a wired
zero: no matter what is written to it, reading from it will always
return 0. That's a useful thing to know; we can now define a storage
class for zero specifically, and define the zero register at offset
0.
The platform ABI uses x1 for a link register (storing the return
address for a subroutine). We may or may not want to use this for our
own return address; I'm not yet sure if we will be able to. For now,
though, we'll keep it reserved for the platform return address,
defining it as register lr in SBCL nomenclature, and use x5 for
our own lisp return address register. Why x5? The ISA definition
for the jalr instruction (Jump And Link Register, logical page 16)
informs us that return address prediction hardware should manipulate
the prediction stack when either x1 or x5 is used as the link
register with jalr, and not when any other register is used; that's
what “Alternate link register” means in the above table. We'll see if
this choice for our lra register,
for Spectre or for worse, gives us
any kind of speed boost – or even if it is tenable at all.
We can define the Number Stack Pointer and Number Frame Pointer
registers, even though we don't need them yet: in SBCL parlance, the
“number” stack is the C stack, and our register table says that those
should be x2 and x8 respectively. Next, for our own purposes we
will need: Lisp stack, frame and old-frame pointer registers; some
function argument registers; and some non-descriptor temporaries.
We'll put those semi-arbitrarily in the temporaries and function
arguments region of the registers; the only bit of forethought here is
to alternate our Lisp arguments and non-descriptor temporaries with
one eye on the “C” RISC-V extension for compressed instructions: if an
instruction uses registers x8–x15 and the “C” extension is
implemented on a particular RISC-V board, the instruction might be
encodable in two bytes instead of four, hopefully reducing instruction
loading and decoding time and instruction cache pressure. (This might
also be overthinking things at this stage). In the spirit of not
overthinking, let's just put nargs on x31 for now.
With
all these decisions implemented,
we hit our first “real” error! Remembering that we are attempting to
compile a very simple file, whose only actual Lisp code involves
returning an element from a specialized array, it's great to hit this
error because it seems to signify that we are almost ready. The
cross-compiler is built knowing that some functions (usually as a
result of code transformations) should never be compiled as calls, but
should instead be /translated/ using one of our Virtual OPerations.
data-vector-ref, which the aref in
our
scratch.lisp file
translates to because of the type declarations, is one such function,
so
we
need to define it:
and also define it in such a way that it will be used no matter what
the current compiler policy, hence the :policy :fast-safe addition
to the reffer macro. (That, and many other such :policy
declarations, are dotted around everywhere in the other backends; I
may come to regret having taken them out in the initial boilerplate
exercise.)
And then, finally, because there's always an excuse for a good
cleanup: those float array VOPs, admittedly without :generator
bodies, look too similar: let's have
a
define-float-vector-frobs macro to
tidy things up. (They may not remain that tidy when we come to
actually implement them). At this point, we have successfully
compiled one Virtual OPeration! I know this, because the next error
from running the build with all this is about call-named, not
data-vector-set. Onward!
I'm on a train! (Disclaimer: I'm not on a train any more.)
What better thing to do, during the hot, hot July days, thank something semi-mechanical involving very little brain power? With student-facing work briefly calming down (we've just about weathered the storm of appeals and complaints following the publication of exam results), and the all-too-brief Summer holidays approaching, I caught myself thinking that it wasn't fair that Doug and his team should have all the fun of porting SBCL to a new architecture; I want a go, too! (The fact that I have no time notwithstanding.)
But, to what? 64-bit powerpc is definitely on the move; I've missed that boat. SBCL already supports most current architectures, and “supports” a fair number of obsolete ones too. One thought that did catch my brain, though, was prompted by the recent publication by ARM of a set of claims purporting to demonstrate the dangers of the RISC-V architecture, in comparison to ARM's own. Well, since SBCL already runs on 32-bit and 64-bit ARM platforms, how hard could porting to RISC-V be?
I don't know the answer to that yet! This first post merely covers the straightforward – some might even say “tedious” – architecture-neutral changes required to get SBCL to the point that it could start about considering compiling code for a new backend.
The SBCL build has roughly seven phases (depending a bit on how you count):
- build configuration;
- build the cross-compiler using the host Lisp, generating target-specific header files;
- build the runtime and garbage collector using a C compiler and platform assembler, generating an executable;
- build the target compiler using the cross-compiler, generating target-specific fasl files;
- build the initial ("cold") image, using the genesis program to simulate the effect of loading fasl files, generating a target Lisp memory image;
- run all the code that stage 5 delayed because it couldn't simulate the effects of loading fasls (e.g. many side-effectful top-level forms);
- build everything else, primarily PCL (a full implementation CLOS) and save the resulting image.
1. Define a keyword for a new backend architecture
Probably the most straightforward thing to do, and something that
allows me to (pretty much) say that we're one seventh of the way
there: defining a new keyword for a new backend architecture is
almost as simple as adding a line or two to
make-config.sh.
Almost.
We run some devious dastardly consistency checks on our target
*features*, and those need to be updated too. This gets
make-config.sh running, and allows make-host-1.sh to run its
consistency checks.
2. Construct minimal backend-specific files
Phase 2, building the cross-compiler, sounds like something straightforward: after all, if we don't have the constraint that the cross-compiler will do anything useful, not even run, then surely just producing minimal files where the build system expects to find them will do, and Lisp’s usual late-binding nature will allow us to get away with the rest. No?
Well, that could have been the case, but SBCL itself does impose some constraints, and the minimal files are a lot less minimal than you might think. The translation of IR2 (second intermediate representation) to machine code involves calling a number of VOPs (virtual operations) by name: and those calls by name perform compile-time checking that the virtual operation template name already exists. So we have to define stub VOPs for all those virtual operations called by name, including those in optimizing vector initialisation, for all of our specialised vector types. These minimal definitions do nothing other than pacify the safety checks in the cross-compiler code.
Phase 2 also generates a number of header files used in the
compilation of the C-based runtime, propagating constant and object
layout definitions to the garbage collector and other support
routines. We won't worry about that for now; we just have to ignore
an error about this at first-genesis time for a while. And with this,
make-host-1.sh runs to completion.
4. Build the target compiler using the cross-compiler
At this point, we have a compiler backend that compiles. It almost
certainly doesn't run, and even when it does run, we will want to ask
it to compile simple forms of our choosing. For now, we
just
add a new file to
the start of the build order, and put in a very simple piece of code,
to see how we get on. (Spoiler alert: not very well). We've added
the :trace-file flag so that the cross-compiler will print
information about its compilation, which will be useful as and when we
get as far as actually compiling things.
The next steps, moving beyond the start of step 4, will involve making decisions about how we are going to support sbcl on RISC-V. As yet, we have not made any decisions about register function (some of those, such as the C stack and frame pointer, will be dictated by the platform ABI, but many won't, such as exactly how we will partition the register set), or about how the stack works (again, the C stack will be largely determined, but Lisp will have its own stack, kept separate for ease of implementating garbage collection).
(Observant readers will note that phase 3 is completely unstarted. It's not necessary yet, though it does need to be completed for phase 4 to run to completion, as some of the cross-compilation depends on information about the runtime memory layout. Some of the details in phase 3 depend on the decisions made in phase 4, though, so that's why I'm doing things in this order, and not, say, because I don't have a RISC-V machine to run anything on -- it was pleasantly straightforward to bring up Fedora under QEMU which should be fine as a place to get started.)
And this concludes the initial SBCL porting work that can be done with very little brain. I do not know where, if anywhere, this effort will go; I am notionally on holiday, and it is also hot: two factors which suggest that work on this, if any, will be accomplished slowly. I'd be very happy to collaborate, if anyone else is interested, or else plod along in my own slow way, writing things up as I go.
Since
approximately forever,
sbcl has advertised the possibility of tracing
individual methods of a generic function by passing :methods t as an
argument to trace. Until
recently, tracing methods was only supported using the :encapsulate
nil style of tracing, modifying the compiled code for function
objects directly.
For a variety of reasons, the alternative :encapsulate t
implementation of tracing, effectively wrapping the function with some
code to run around it, is more robust. One problem with :encapsulate
nil tracing is that if the object being traced is a closure, the
modification of the function's code will affect all of the closures,
not just any single one – closures are distinct objects with distinct
closed-over environments, but they share the same execuable code, so
modifying one of them modifies all of them. However, the
implementation of method tracing I wrote in 2005 – essentially,
finding and tracing the method functions and the method fast-functions
(on which more later) – was fundamentally incompatible with
encapsulation; the method functions are essentially never called by
name by CLOS, but by more esoteric means.
What are those esoteric means, I hear you ask?! I'm glad I can hear
you. The Metaobject Protocol defines a method calling convention,
such that method calls receive as two arguments firstly: the entire
argument list as the method body would expect to handle; and secondly:
the list of sorted applicable next methods, such that the first
element is the method which should be invoked if the method
uses
call-next-method. So
a method function conforming to this protocol has to:
- destructure its first argument to bind the method parameters to the arguments given;
- if
call-next-methodis used, reconstruct an argument list (in general, because the arguments to the next method need not be the same as the arguments to the existing method) before calling the next method’s method-function with the reconstructed argument list and the rest of the next methods.
But! For a given set of actual arguments, for that call, the set of
applicable methods is known; the precedence order is known; and, with
a bit of bookkeeping in the implementation
of defmethod, whether any
individual method actually calls call-next-method is known. So it
is possible, at the point of calling a generic-function with a set of
arguments, to know not only the first applicable method, but in fact
all the applicable methods, their ordering, and the combination of
those methods that will actually get called (which is determined by
whether methods invoke call-next-method and also by the generic
function’s method combination).
Therefore, a sophisticated (and by “sophisticated” here I mean
“written by the wizards
at Xerox PARC)”)
implementation of CLOS can compile an effective method for a given
call, resolve all the next-method calls, perform
some
extra optimizations on
slot-value and slot
accessors, improve the calling convention (we no longer need the list
of next methods, but only a single next effective-method, so we can
spread the argument list once more), and cache the resulting function
for future use. So the one-time cost for each set of applicable
methods generates an optimized effective method, making use of
fast-method-functions with the improved calling convention.
Here's the trick, then: this effective method is compiled into a chain
of method-call and fast-method-call objects, which call their
embedded functions. This, then, is ripe for encapsulation; to allow
method tracing, all we need to do is arrange at
compute-effective-method time that those embedded functions are
wrapped in code that performs the tracing, and that any attempt to
untrace the generic function (or to modify the tracing parameters)
reinitializes the generic function instance, which clears all the
effective method caches. And then Hey Bob, Your Uncle’s Presto! and
everything works.
(defgeneric foo (x)
(:method (x) 3))
(defmethod foo :around ((x fixnum))
(1+ (call-next-method)))
(defmethod foo ((x integer))
(* 2 (call-next-method)))
(defmethod foo ((x float))
(* 3 (call-next-method)))
(defmethod foo :before ((x single-float))
'single)
(defmethod foo :after ((x double-float))
'double)
Here's a generic function foo with moderately complex methods. How
can we work out what is going on? Call the method tracer!
CL-USER> (foo 2.0d0)
0: (FOO 2.0d0)
1: ((SB-PCL::COMBINED-METHOD FOO) 2.0d0)
2: ((METHOD FOO (FLOAT)) 2.0d0)
3: ((METHOD FOO (T)) 2.0d0)
3: (METHOD FOO (T)) returned 3
2: (METHOD FOO (FLOAT)) returned 9
2: ((METHOD FOO :AFTER (DOUBLE-FLOAT)) 2.0d0)
2: (METHOD FOO :AFTER (DOUBLE-FLOAT)) returned DOUBLE
1: (SB-PCL::COMBINED-METHOD FOO) returned 9
0: FOO returned 9
9
This mostly works. It doesn’t quite handle all cases, specifically
when the CLOS user adds a method and implements call-next-method for
themselves:
(add-method #'foo
(make-instance 'standard-method
:qualifiers '()
:specializers (list (find-class 'fixnum))
:lambda-list '(x)
:function (lambda (args nms) (+ 2 (funcall (sb-mop:method-function (first nms)) args (rest nms))))))
CL-USER> (foo 3)
0: (FOO 3)
1: ((METHOD FOO :AROUND (FIXNUM)) 3)
2: ((METHOD FOO (FIXNUM)) 3)
2: (METHOD FOO (FIXNUM)) returned 8
1: (METHOD FOO :AROUND (FIXNUM)) returned 9
0: FOO returned 9
9
In this trace, we have lost the method trace from the direct call to
the method-function, and calls that that function makes; this is
the cost of performing the trace in the effective method, though a
mitigating factor is that we have visibility of method combination
(through the (sb-pcl::combined-method foo) line in the trace above).
It would probably be possible to do the encapsulation in the method
object itself, by modifying the function and the fast-function, but
this requires rather more book-keeping and (at least theoretically)
breaks the object identity: we do not have licence to modify the
function stored in a method object. So, for now, sbcl has this
imperfect solution for users to try (expected to be in sbcl-1.4.9,
probably released towards the end of June).
(I can't really believe it’s taken me twelve years to do this. Other implementations have had this working for years. Sorry!)
At the 2018 European Lisp Symposium, the most obviously actionable feedback for SBCL from a presentation was from Didier's remorseless deconstruction of SBCL's support for method combinations (along with the lack of explicitness about behavioural details in the ANSI CL specification and the Art of the Metaobject Protocol). I don't think that Didier meant to imply that SBCL was particularly bad at method combinations, compared with other available implementations – merely that SBCL was a convenient target. And, to be fair, there was a bug report from a discussion with Bruno Haible back in SBCL's history – May/June 2004, according to my search – which had languished largely unfixed for fourteen years.
I said that I found the Symposium energising.
And what better use to put that energy than addressing user feedback?
So, I spent a bit of time earlier this month thinking, fixing and
attempting to work out what behaviours might actually be useful. To
be clear, SBCL’s support for define-method-combination was (probably)
standards-compliant in the usual case, but if you follow the links
from above, or listen to Didier’s talk, you will be aware that that’s
not saying all that much, in that almost nothing is specified about
behaviours under redefinition of method combinations.
So, to start with, I solved the cache invalidation (one of
the
hardest problems in Computer Science),
making sure that discriminating functions and effective methods are
reset and invalidated for all affected generic functions. This was
slightly complicated by the strategy that SBCL has of distinguishing
short and long method-combinations with distinct classes (and distinct
implementation strategies
for
compute-effective-method);
but this just needed to be methodical and careful. Famous last words:
I think that all method-combination behaviour in SBCL is now coherent
and should meet user expectations.
More interesting, I think, was coming up with test cases for desired
behaviours. Method combinations are not, I think, widely used in
practice; whether that is because of lack of support, lack of
understanding or lack of need of what they provide, I don't know. (In
fact in conversations at ELS we discussed another possibility, which
is that everyone is more comfortable customising
compute-effective-method instead – both that and
define-method-combination provide ways for inserting arbitrary code
for the effect of a generic function call with particular arguments.
But what this means is that there isn’t, as far as I know at least, a
large corpus of interesting method combinations to play with.
One interesting one which came up: Bike on #lisp designed
an
implementation using method-combinations of finite state machines,
which I adapted to add to SBCL’s test suite. My version looks like:
(define-method-combination fsm (default-start)
((primary *))
(:arguments &key start)
`(let ((state (or ,start ',default-start)))
(restart-bind
(,@(mapcar (lambda (m) `(,(first (method-qualifiers m))
(lambda ()
(setq state (call-method ,m))
(if (and (typep state '(and symbol (not null)))
(find-restart state))
(invoke-restart state)
state))))
primary))
(invoke-restart state))))
and there will be more on this use
of restart-bind in a
later post, I hope. Staying on the topic of method combinations, how
might one use this fsm method combination? A simple example might
be to recognize strings with an even number of #\a characters:
;;; first, define something to help with all string parsing
(defclass info ()
((string :initarg :string)
(index :initform 0)))
;;; then the state machine itself
(defgeneric even-as (info &key &allow-other-keys)
(:method-combination fsm :yes))
(defmethod even-as :yes (info &key)
(with-slots ((s string) (i index)) info
(cond ((= i (length s)) t) ((char= (char s i) #\a) (incf i) :no) (t (incf i) :yes))))
(defmethod even-as :no (info &key)
(with-slots ((s string) (i index)) info
(cond ((= i (length s)) nil) ((char= (char s i) #\a) (incf i) :yes) (t (incf i) :no))))
(Exercise for the reader: adapt this to implement a Turing Machine)
Another example of (I think) an interesting method combination was one which I came up with in the context of generalized specializers, for an ELS a while ago: the HTTP Request method-combination to be used with HTTP Accept specializers. I'm interested in more! A github search found some examples before I ran out of patience; do you have any examples?
And I have one further question. The method combination takes
arguments at generic-function definition time (the :yes in
(:method-combination fsm :yes)). Normally, arguments to things are
evaluated at the appropriate time. At the moment, SBCL (and indeed
all other implementations I tested, but that's not strong evidence
given the shared heritage) do not evaluate the arguments to
:method-combination – treating it more like a macro call than a
function call. I’m not sure that is the most helpful behaviour, but
I’m struggling to come up with an example where the other is
definitely better. Maybe something like
(let ((lock (make-lock)))
(defgeneric foo (x)
(:method-combination locked lock)
(:method (x) ...)))
Which would allow automatic locking around the effective method of
FOO through the method combination? I need to think some more here.
In any case: the method-combination fixes are in the current SBCL
master branch, shortly to be released as sbcl-1.4.8. And there is
still time (though not very much!) to apply for
the
many jobs advertised
at
Goldsmiths Computing –
what better things to do on a Bank Holiday weekend?
I presented some of the work on teaching algorithms and data structures at the 2018 European Lisp Symposium
Given that I wanted to go to the symposium (and I’m glad I did!), the most economical method for going was if I presented research work – because then there was a reasonable chance that my employer would fund the expenses (spoiler: they did; thank you!). It might perhaps be surprising to hear that they don’t usually directly fund attending events where one is not presenting; on the other hand, it’s perhaps reasonable on the basis that part of an academic’s job as a scholar and researcher is to be creating and disseminating new knowledge, and of course universities, like any organizations, need to prioritise spending money on things which bring value or further the organization’s mission.
In any case, I found that I wanted to write about the teaching work that I have been doing, and in particular I chose to write about a small, Lisp-related aspect. Specifically, it is now fairly normal in technical subjects to perform a lot of automated testing of students; it relieves the burden on staff to assess things which can be mechanically assessed, and deliver feedback to individual students which can be delivered automatically; this frees up staff time to perform targeted interventions, give better feedback on more qualitative aspects of the curriculum, or work fewer weekends of the year. A large part of my teaching work for the last 18 months has been developing material for these automated tests, and working on the infrastructure underlying them, for my and colleagues’ teaching.
So, the more that we can test automatically and meaningfully, the
more time we have to spend on other things. The main novelty here,
and the lisp-related hook for the paper I submitted to ELS, was being
able to give meaningful feedback on numerical answer questions which
probed whether students were developing a good mental model of the
meaning of pseudocode. That’s a bit vague; let’s be specific and
consider the break and continue keywords:
x ← 0
for 0 ≤ i < 9
x ← x + i
if x > 17
continue
end if
x ← x + 1
end for
return x
The above pseudocode is typical of what a student might see; the
question would be “what does the above block of pseudocode return?”,
which is mildly arithmetically challenging, particularly under time
pressure, but the conceptual aspect that was being tested here was
whether the student understood the effect of continue. Therefore,
it is important to give the student specific feedback; the more
specific, the better. So if a student answered 20 to this question
(as if the continue acted as a break), they would receive a
specific feedback message reminding them about the difference between
the two operators; if they answered 45, they received a message
reminding them that continue has a particular meaning in loops; and
any other answers received generic feedback.
Having just one of these questions does no good, though. Students will go to almost any lengths to avoid learning things, and it is easy to communicate answers to multiple-choice and short-answer questions among a cohort. So, I needed hundreds of these questions: at least one per student, but in fact by design the students could take these multiple-chocie quizzes multiple times, as they are primarily an aid for the students themselves, to help them discover what they know.
Now of course I could treat the above pseudocode fragment as a
template, parameterise it (initial value, loop bounds, increment) and
compute the values needing the specific feedback in terms of the
values of the parameters. But this generalizes badly: what happens
when I decide that I want to vary the operators (say to introduce
multiplication) or modify the structure somewhat (e.g. by swapping
the two increments before and after the continue)? The
parametrization gets more and more complicated, the chances of (my)
error increase, and perhaps most importantly it’s not any fun.
Instead, what did I do? With some sense of grim inevitability, I
evolved (or maybe accreted) an interpreter (in emacs lisp) for a
sexp-based representation of this pseudocode. At the start of the
year, it's pretty simple; towards the end it has developed into an
almost reasonable mini-language. Writing the interpreter is
straightforward, though the way it evolved into one gigantic case
statement for supported operators rather than having reasonable
semantics is a bit of a shame; as a bonus, implementing a
pretty-printer for the sexp-based pseudocode, with correct indentation
and keyword highlighting, is straightforward. Then armed with the
pseudocode I will ask the students to interpret, I can mutate it in
ways that I anticipate students might think like (replacing continue
with break or progn) and interpret that form to see which wrong
answer should generate what feedback.
Anyway, that was the hook. There's some evidence in the paper that the general approach of repeated micro-assessment, and also the the consideration of likely student mistakes and giving specific feedback, actually works. And now that the (provisional) results are in, how does this term compare with last term? We can look at the relationship between this term’s marks and last term’s. What should we be looking for? Generally, I would expect marks in the second term’s coursework to be broadly similar to the marks in the first term – all else being equal, students who put in a lot of effort and are confident with the material in term 1 are likely to have an easier time integrating the slightly more advanced material in term 2. That’s not a deterministic rule, though; some students will have been given a wake-up call by the term 1 marks, and equally some students might decide to coast.
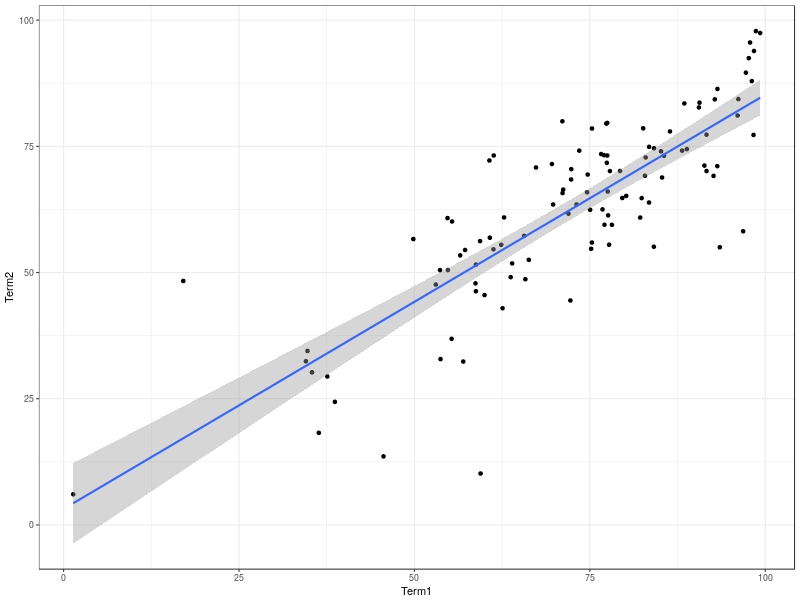
I’ve asked R to draw the regression line in the above picture; a straight line fit seems reasonable based on the plot. What are the statistics of that line?
R> summary(lm(Term2~Term1, data=d))
Call:
lm(formula = Term2 ~ Term1, data = d)
Residuals:
Min 1Q Median 3Q Max
-41.752 -6.032 1.138 6.107 31.155
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 3.18414 4.09773 0.777 0.439
Term1 0.82056 0.05485 14.961 <2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 10.46 on 107 degrees of freedom
(32 observations deleted due to missingness)
Multiple R-squared: 0.6766, Adjusted R-squared: 0.6736
F-statistic: 223.8 on 1 and 107 DF, p-value: < 2.2e-16
Looking at the summary above, we have a strong positive relationship between term 1 and term 2 marks. The intercept is approximately zero (if you got no marks in term 1, you should expect no marks in term 2), and the slope is less than one: on average, each mark a student got in term 1 tended to convert to 0.8 marks in term 2 – this is plausibly explained by the material being slightly harder in term 2, and by the fact that some of the assessments were more explicitly designed to allow finer discrimination at the top end – marks in the 90s. (A note for international readers: in the UK system, the pass mark is 40%, excellent work is typically awarded a mark in the 70% range – marks of 90% should be reserved for exceptional work). The average case is, however, only that: there was significant variation from that average line, and indeed (looking at the quartiles) over 50% of the cohort was more than half a degree class (5 percentage points) away from their term 2 mark as “predicted” from their mark for term 1.
All of this seems reasonable, and it was a privilege to work with this cohort of students, and to present the sum of their interactions on this course to the audience I had. I got the largest round of applause, I think, for revealing that as part of the peer-assessment I had required that students run each others’ code. I also had to present some of the context for the work; not only because this was an international gathering, with people in various university systems and from industry, but also because of the large-scale disruption caused by industrial action over the Universities Superannuation Scheme (the collective, defined benefit pension fund for academics at about 68 Universities and ~300 other bodies associated with Higher Education). Perhaps most gratifyingly, students were able to continue learning despite being deprived of their tuition for three consecutive weeks; judging by their performance on the various assessments so far,
And now? The students will sit an exam, after which I and colleagues will look in detail at those results and the relationship with the students’ coursework marks (as I did last year). I will continue developing this material (my board for this module currently lists 33 todo items), and adapt it for next year and for new cohorts. And maybe you will join me? The Computing department at Goldsmiths is hiring lecturers and senior lecturers to come and participate in research, scholarship and teaching in computing: a lecturer in creative computing, a lecturer in computer games, a lecturer in data science, a lecturer in physical and creative computing, a lecturer in computer science and a senior lecturer in computer science. Anyone reading this is welcome to contact me to find out more!
I didn't quite get round to voting in
this last year's IFComp.
(Oops, I didn't quite get round to posting this when it was topical.)
I did play some of the submissions, though. In particular I played under competition terms most of the Inform parser games, and I had fun doing it. My personal favourite, which probably reflects my background as some flavour of mathematician, was A beauty cold and austere: you have twelve hours to learn enough mathematics to pass your end-of-term test. The pharmaceutical-induced dream conceit allowed the somewhat unconnected puzzles to be combined without worrying too much about a theme – beyond mathematics! – and those puzzles were generally fair. I played for the competition-mandated time of two hours without the walkthrough, though with enough formal mathematical education that using a walkthrough would really have felt like cheating; I did need some help of the “what to do next” kind to finish the game.
The wand I played for a while. It was nice to see a different game mechanic in play (the only things you can do in this game is wave a magic wand, and change the colour combinations of the wand), and the game gave clear direction on how to get started. But I am a person of insufficient persistence, and my reaction to the discovery that I was going to have to remember tens of colour combinations in order to do anything was to write grouchy stuff in my notes about how it would have been better to unlock verbs rather than mess around with the colours all the time and writing down all the combinations I'd discovered...
... which meant that I missed about 90% of the game, I later discovered. If I had been consciously aware that The wand was written by Arthur DiBianca, who wrote Grandma Bethlinda's Variety Box, I might have put in the time investment. Learn from my mistake!
The winner of IFComp was The Wizard Sniffer, which like The wand restricts your actions to an almost absurd degree (maybe not absurd for a pig). Unlike The wand, which is essentially entirely puzzle-focussed, The Wizard Sniffer has a surface narrative that is engaging, as well as a more subversive narrative that unfolds as the puzzles in the game are solved. I can absolutely see why this appeals to game-players; it was just below A beauty cold and austere in my personal ratings, and I definitely did not have the patience to solve some of the puzzles without walkthrough assistance, but I recognize that the framing (reminiscent of Lloyd Alexander’s Taran and Hen-Wen cycle, with additional social commentary) and the quality of the writing in The Wizard Sniffer make it a worthy competition winner.
Some of the other parser games I found less successful: Rainbow bridge was simple and charming, but without any particular challenge; Ultimate escape room didn't really use the medium for anything, and had one particularly annoying guess-the-verb and-also-the-noun puzzle; 8 shoes on the shelves I simply did not understand – quite possibly I missed something. I also started The Owl consults and Eat me, but at this point ran out of time by being thoroughly enmired in developing teaching materials for my Algorithms & Data Structures class, and in fact got so thoroughly consumed by that that it is only now, seven months later, that I revisit this blog entry.
What of non-parser games? I find it interesting that the top-placed games are almost all parser-based, whether Inform, TADS or something else; given that, I'm intrigued by the very-highly-scoring Harmonia, which is built in the Liza Daly (the author's) own Windrush game engine; she also has a post-competition article about the design of interactive marginalia used in the story. It being past the end of teaching term now, I might have hoped that I could indulge, except that I need to start work on next term's materials – and no, I'm not convinced that playing more IF is sufficiently high on the priority list of preparation for teaching Narrative & Interactive Fiction in January. I will play vicariously through my students, and wait for Easter.
A few weeks ago, I attended the 2018 European Lisp Symposium.
If you were at the 2017 iteration, you might (as I do) have been left with an abiding image of greyness. That was not at all to fault the location (Brussels) or the organization (co-located with ) of the symposium; however, the weather was unkind, and that didn't help with my own personal low-energy mood at the time.
This year, the event was organized
by Ravenpack in Marbella. And the first
thing that I noticed on landing was the warmth. (Perhaps the only
“perk” of low-cost airlines is that it is most likely that one will
disembark on to terra firma rather than a passenger boarding bridge.
And after quite a miserable winter in the UK, the warmth and the
sunshine at the bus stop, while waiting for the bus from Malagá
airport to Marbella, was very welcome indeed. The sense of community
was strong too; while waiting for the bus, I hopped on to
#lisp IRC and Nic Hafner volunteered to meet me at the Marbella bus
station and walk with me to my hotel; we ended up going for drinks at
a beachside bar that evening with Dimitri Fontaine, Christian
Schafmeister, Mikhail Raskin and others – and while we were sitting
there, enjoying the setting, I saw other faces I recognised walking
past along the beach promenade.
The setting for the conference itself, the Centro Cultural Cortijo de Miraflores, was charming. We had the use of a room, just about big enough for the 90ish delegates; the centre is the seat of the Marbella Historical Archives, and our room was next to the olive oil exhibition.

We also had an inside courtyard for the breaks; sun, shade, water and
coffee were available in equal measure, and there was space for good
conversations – I spoke with many people, and it was great to catch up
and reminisce with old friends, and to discuss the finer points of
language implementation and release management with new ones. (I
continue to maintain that the SBCL time-boxed monthly release cadence
of master, initiated by Bill Newman way back in the SBCL 0.7 days in
2002 [!], has two distinct advantages, for our situation, compared
with other possible choices, and I said so more than once over
coffee.)
The formal programme, curated by Dave Cooper, was great too. Zach's written about his highlights; I enjoyed hearing Jim Newton's latest on being smarter about typecase, and Robert Smith's presentation about quantum computing, including a walkthrough of a quantum computing simulator. As well as quantum computing, application areas mentioned in talks this year included computational chemistry, data parallel processing, pedagogy, fluid dynamics, architecture, sentiment analysis and enterprise resource planning – and there were some implementation talks in there too, not least from R. “it’s part of the brand” Matthew Emerson, who gave a paean to Clozure Common Lisp. Highly non-scientific SBCL user feedback from ELS presenters: most of the speakers with CL-related talks or applications at least mentioned SBCL; most of those mentions by speaker were complimentary, but it's possible that most by raw count referred to bugs – solely due to Didier Verna's presentation about method combinations (more on this in a future blog post).
Overall, I found this year's event energising. I couldn't be there any earlier than the Sunday evening, nor could I stay beyond Wednesday morning, so I missed at least the organized social event, but the two days I had were full and stress-free (even when chairing sessions and for my own talk). The local organization was excellent; Andrew Lawson, Nick Levine and our hosts at the foundation did us proud; we had a great conference dinner, and the general location was marvellous.
Next year's event will once again be co-located with <Programming>, this time in Genova (sunny!) on 1st-2nd April 2019. Put it in your calendar now!