Possible alternative title: I’m on a train!
In particular, I’m on the train heading to the European Lisp Symposium, and for the first time since December I don’t have a criticially urgent piece of teaching to construct. (For the last term, I’ve been under the cosh of attempting to teach Algorithms & Data Structures to a class, having never learnt Algorithms & Data Structures formally, let along properly, myself).
I have been giving the students some structure to help them in their learning by constructing multiple-choice quizzes. “But multiple-choice quizzes are easy!”, I hear you cry! Well, they might be in general, but these quizzes were designed to probe some understanding, and to help students recognize what they did not know; of the ten quizzes I ran this term, several had a period where the modal mark in the quiz was zero. (The students were allowed take the quizzes more than once; the idea behind that being that they can learn from their mistakes and improve their score; the score is correlated to a mark in some minor way to act as a tiny carrot-bite of motivation; this means I have to write lots of questions so that multiple attempts aren’t merely an exercise in memory or screenshot navigation).
The last time I was on a train, a few weeks ago, I was travelling to and from Warwick to sing Haydn’s Nelson Mass (“Missa in angustiis”; troubled times, indeed), and had to write a quiz on numbers. I’d already decided that I would show the students the clever Karatsuba trick for big integer multiplication, and I wanted to write some questions to see if they’d understood it, or at least could apply some of the results of it.
Standard multiplication as learnt in school is, fairly clearly, an Ω(d2) algorithm. My children learn to multiply using the “grid method”, where: each digit value of the number is written out along the edges of a table; the cells of the table are the products of the digit values; and the result is found by adding the cells together. Something like:
400 20 7
300 120000 6000 2100
90 36000 1800 630
3 1200 60 21
for 427×393 = 167811. Similar diagrammatic ways of multiplying (like [link]) duplicate this table structure, and traditional long multiplication or even the online multiplication trick where you can basically do everything in your head all multiply each digit of one of the multiplicands with each digit of the other.
But wait! This is an Algorithms & Data Structures class, so there must be some recursive way of decomposing the problem into smaller problems; divide-and-conquer is classic fodder for Computer Scientists. So, write a×b as (ahi×2k+alo)×(bhi×2k+blo), multiply out the brackets, and hi and lo and behold we have ahi×bhi×22k+(ahi×blo+alo×bhi)×2k+alo×blo, and we’ve turned our big multiplication into four multiplications of half the size, with some additional simpler work to combine the results, and big-O dear! that’s still quadratic in the number of digits to multiply. Surely there is a better way?
Yes there is. Karatsuba multiplication is a better (asymptotically at least) divide-and-conquer algorithm. It gets its efficiency from a clever observation[1]: that middle term in the expansion is expensive, and in fact we can compute it more cheaply. We have to calculate chi=ahi×bhi and clo=alo×blo, there’s no getting around that, but to get the cross term we can compute (ahi+alo)×(bhi+blo) and subtract off chi and clo: and that’s then one multiply for the result of two. With that trick, Karatsuba multiplication lets us turn our big multiplication into three multiplications of half the size, and that eventaully boils down to an algorithm with complexity Θ(d1.58) or thereabouts. Hooray!
Some of the questions I was writing for the quiz were for the students to compute the complexity of variants of Karatsuba’s trick: generalize the trick to cross-terms when the numbers are divided into thirds rather than halves, or quarters, and so on. You can multiply numbers by doing six multiplies of one-third the size, or ten multiplies of one-quarter the size, or... wait a minute! Those generalizations of Karatsuba’s trick are worse, not better! That was completely counter to my intuition that a generalization of Karatsuba’s trick should be asymptotically better, and that there was probably some sense in which the limit of doing divide-bigly-and-conquer-muchly would turn into an equivalent of FFT-based multiplication with Θ(d×log(d)) complexity. But this generalization was pulling me back towards Θ(d2)! What was I doing wrong?
Well what I was doing wrong was applying the wrong generalization. I don’t feel too much shame; it appears that Karatsuba did the same. If you’re Toom or Cook, you probably see straight away that the right generalization is not to be clever about how to calculate cross terms, but to be clever about how to multiply polynomials: treat the divided numbers as polynomials in 2k, and use the fact that you need one more value than the polynomial’s degree to determine all its coefficients. This gets you a product in five multiplications of one-third the size, or seven multiplications of one-quarter, and this is much better and fit with my intuition as to what the result should be. (I decided that the students could do without being explicitly taught about all this).
Meanwhile, here I am on my train journey of relative freedom, and I thought it might be interesting to see whether and where there was any benefit to implement Karatsuba multiplication in SBCL. (This isn’t a pedagogy blog post, or an Algorithms & Data Structures blog post, after all; I’m on my way to a Lisp conference!). I had a go, and have a half-baked implementation: enough to give an idea. It only works on positive bignums, and bails if the numbers aren’t of similar enough sizes; on the other hand, it is substantially consier than it needs to be, and there’s probably still some room for micro-optimization. The results?
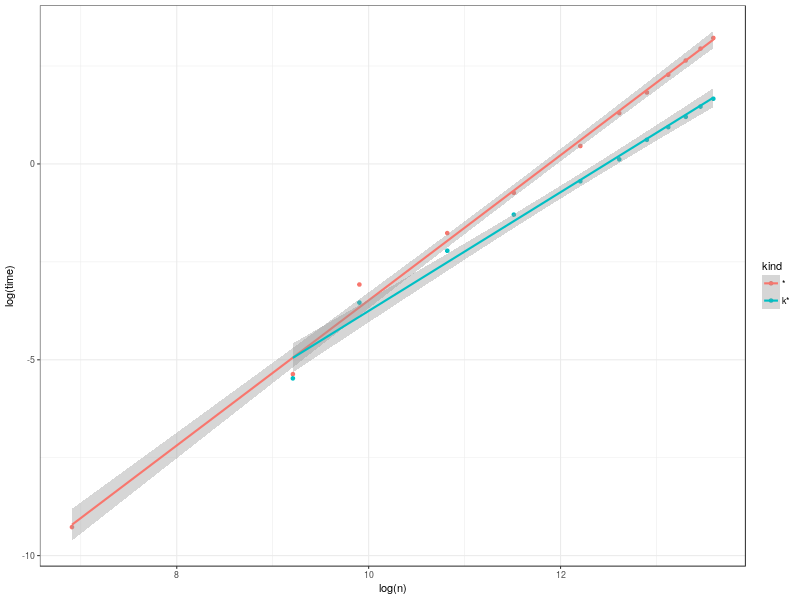
The slopes on the built-in and Karatsuba mulitply (according to the linear model fit) are 1.85±0.04 and 1.52±0.1 respectively, so even million-(binary)-digit bignums aren’t clearly in the asymptotic régimes for the two multiplication methods: but at that size (and even at substantially smaller sizes, though not quite yet at Juho’s 1000 bits) my simple Karatsuba implementation is clearly faster than the built-in multiply. I should mention that at least part of the reason that I have even heard of Karatsuba multiplication is Raymond Toy’s implementation of it in CMUCL.
Does anyone out there use SBCL for million-digit multiplications?